Training Equilibria in Reinforcement Learning
{kind=link}
Abstract
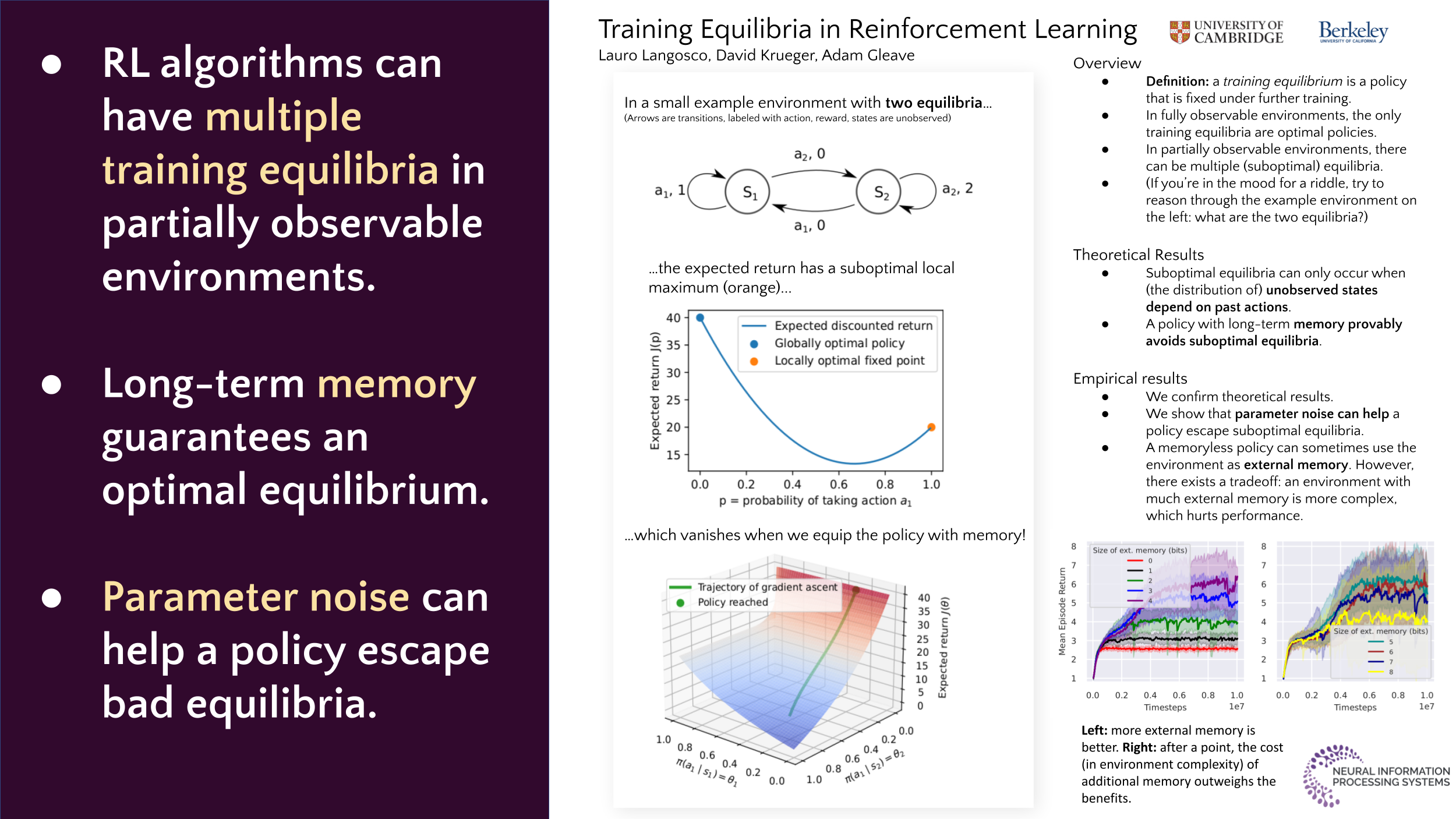
In partially observable environments, reinforcement learning algorithms such as policy gradient and Q-learning may have multiple equilibria---policies that are stable under further training---and can converge to equilibria that are strictly suboptimal. Prior work blames insufficient exploration, but suboptimal equilibria can arise despite full exploration and other favorable circumstances like a flexible policy parametrization.We show theoretically that the core problem is that in partially observed environments, an agent's past actions induce a distribution on hidden states.Equipping the policy with memory helps it model the hidden state and leads to convergence to a higher reward equilibrium, \emph{even when there exists a memoryless optimal policy}.Experiments show that policies with insufficient memory tend to learn to use the environment as auxiliary memory, and parameter noise helps policies escape suboptimal equilibria.