Dual Mean-Teacher: An Unbiased Semi-Supervised Framework for Audio-Visual Source Localization
Yuxin Guo ⋅ Shijie Ma ⋅ Hu Su ⋅ Zhiqing Wang ⋅ Yuhao Zhao ⋅ Wei Zou ⋅ Siyang Sun ⋅ Yun Zheng
2023 Poster
{kind=link}
Abstract
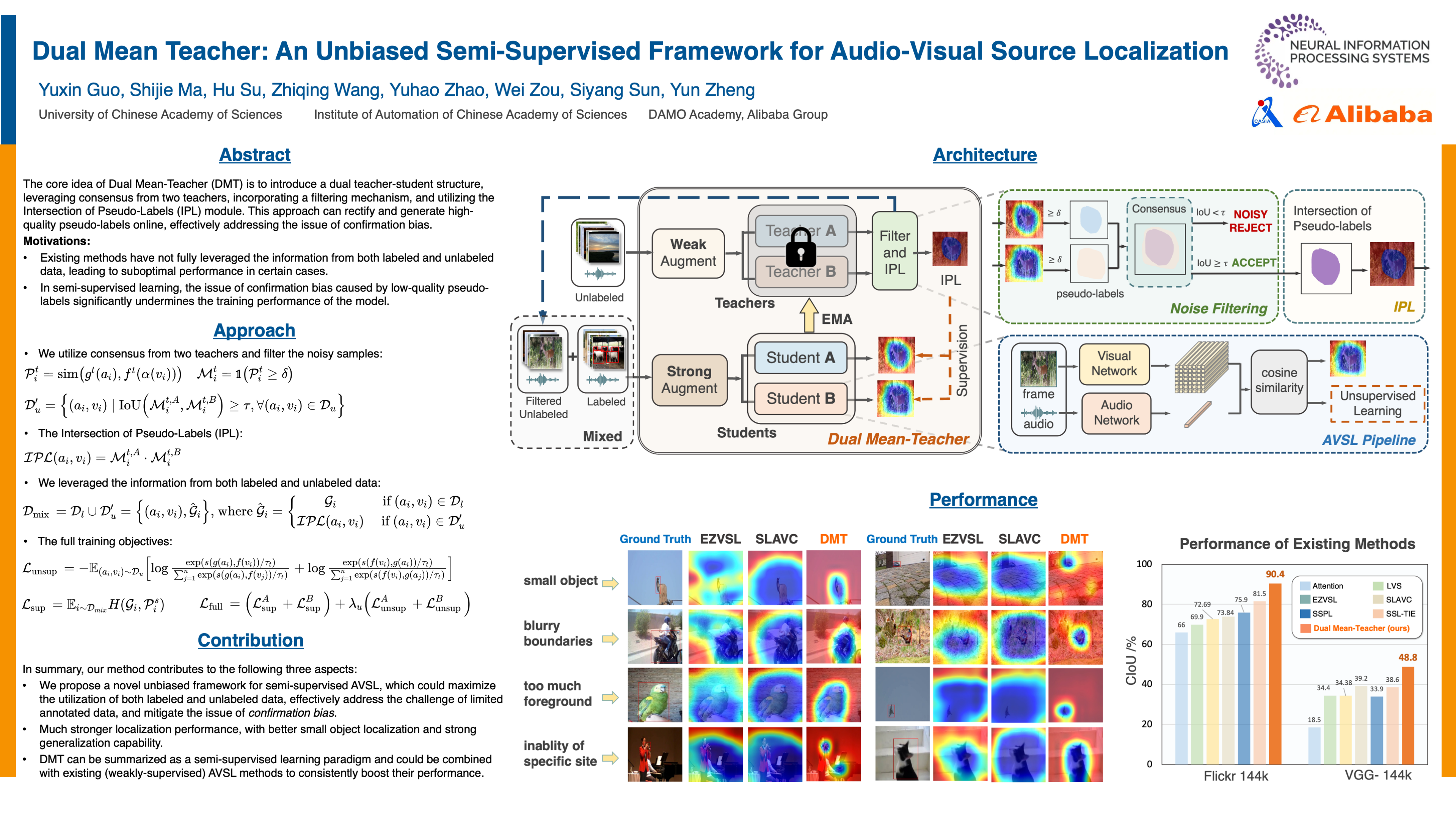
Audio-Visual Source Localization (AVSL) aims to locate sounding objects within video frames given the paired audio clips. Existing methods predominantly rely on self-supervised contrastive learning of audio-visual correspondence. Without any bounding-box annotations, they struggle to achieve precise localization, especially for small objects, and suffer from blurry boundaries and false positives. Moreover, the naive semi-supervised method is poor in effectively utilizing the abundance of unlabeled audio-visual pairs. In this paper, we propose a novel Semi-Supervised Learning framework for AVSL, namely Dual Mean-Teacher (DMT), comprising two teacher-student structures to circumvent the confirmation bias issue. Specifically, two teachers, pre-trained on limited labeled data, are employed to filter out noisy samples via the consensus between their predictions, and then generate high-quality pseudo-labels by intersecting their confidence maps. The optimal utilization of both labeled and unlabeled data combined with this unbiased framework enable DMT to outperform current state-of-the-art methods by a large margin, with CIoU of $\textbf{90.4\%}$ and $\textbf{48.8\%}$ on Flickr-SoundNet and VGG-Sound Source, obtaining $\textbf{8.9\%}$ and $\textbf{9.6\%}$ improvements respectively, given only $3\%$ of data positional-annotated. We also extend our framework to some existing AVSL methods and consistently boost their performance. Our code is publicly available at https://github.com/gyx-gloria/DMT.
Video
Chat is not available.
Successful Page Load