Reward-agnostic Fine-tuning: Provable Statistical Benefits of Hybrid Reinforcement Learning
{kind=link}
Abstract
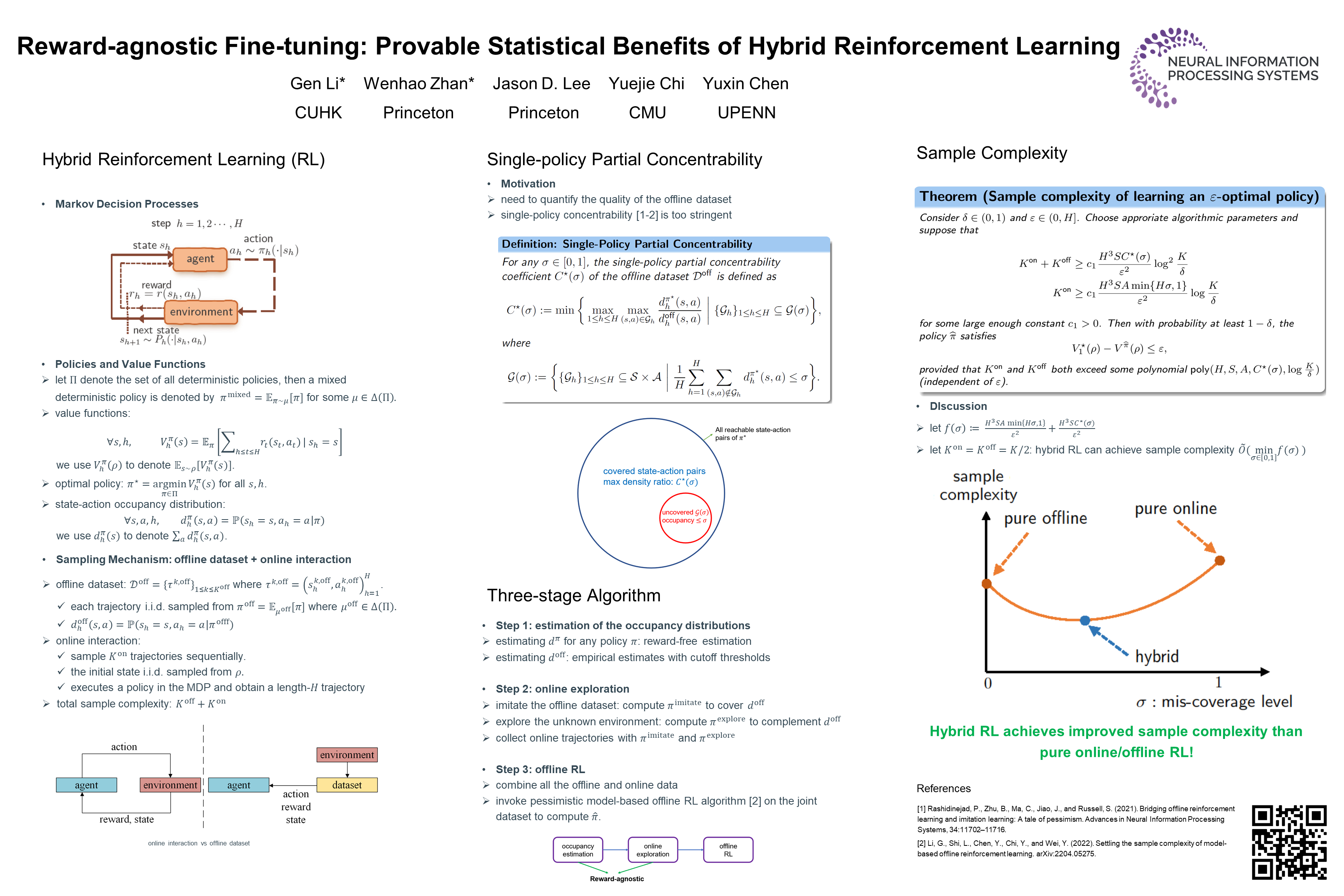
This paper studies tabular reinforcement learning (RL) in the hybrid setting, which assumes access to both an offline dataset and online interactions with the unknown environment. A central question boils down to how to efficiently utilize online data to strengthen and complement the offline dataset and enable effective policy fine-tuning. Leveraging recent advances in reward-agnostic exploration and offline RL, we design a three-stage hybrid RL algorithm that beats the best of both worlds --- pure offline RL and pure online RL --- in terms of sample complexities. The proposed algorithm does not require any reward information during data collection. Our theory is developed based on a new notion called single-policy partial concentrability, which captures the trade-off between distribution mismatch and miscoverage and guides the interplay between offline and online data.