Knowledge Distillation Performs Partial Variance Reduction
{kind=link}
Abstract
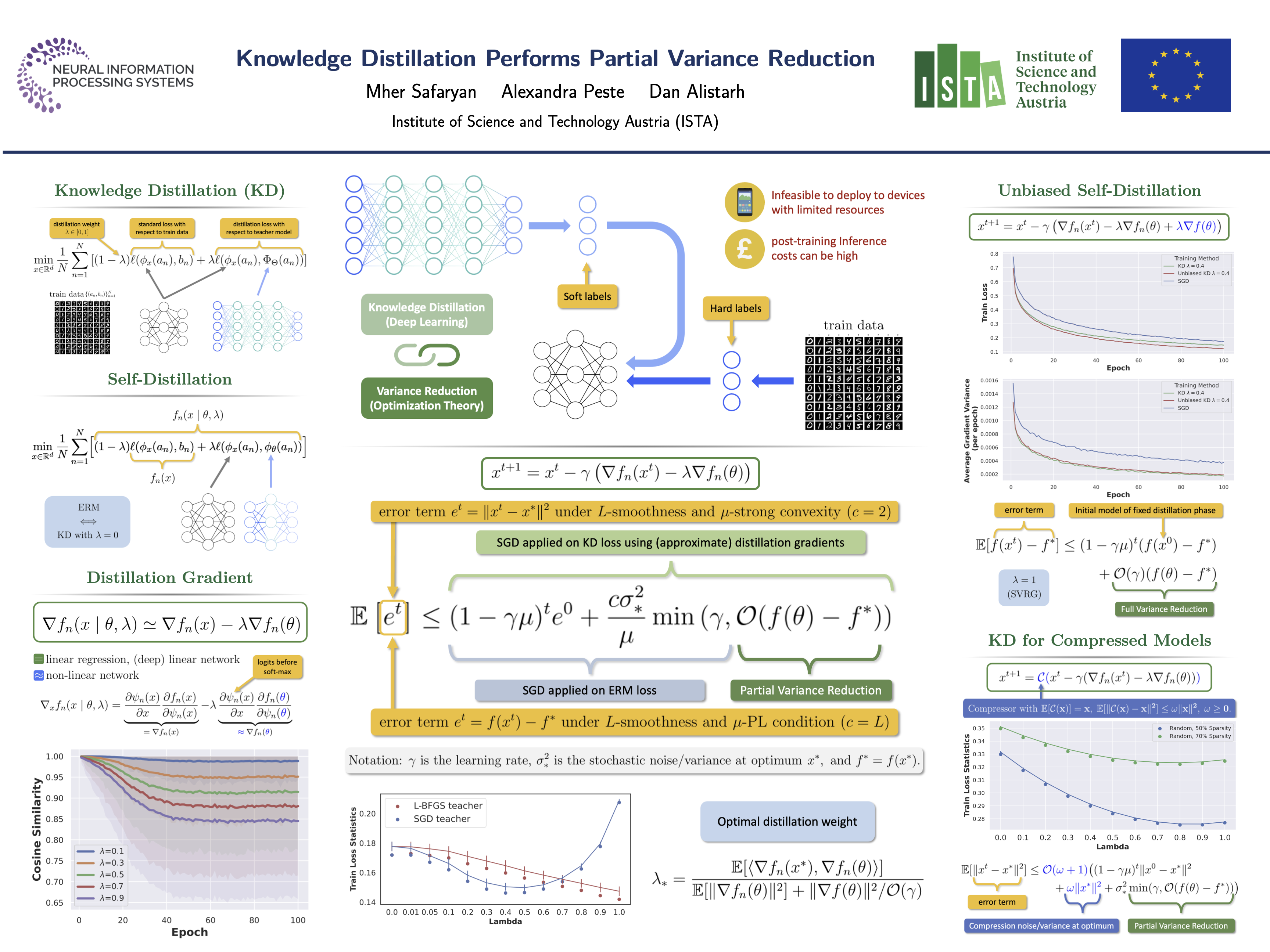
Knowledge distillation is a popular approach for enhancing the performance of "student" models, with lower representational capacity, by taking advantage of more powerful "teacher" models. Despite its apparent simplicity, the underlying mechanics behind knowledge distillation (KD) are not yet fully understood. In this work, we shed new light on the inner workings of this method, by examining it from an optimization perspective. Specifically, we show that, in the context of linear and deep linear models, KD can be interpreted as a novel type of stochastic variance reduction mechanism. We provide a detailed convergence analysis of the resulting dynamics, which hold under standard assumptions for both strongly-convex and non-convex losses, showing that KD acts as a form of \emph{partial variance reduction}, which can reduce the stochastic gradient noise, but may not eliminate it completely, depending on the properties of the ``teacher'' model. Our analysis puts further emphasis on the need for careful parametrization of KD, in particular w.r.t. the weighting of the distillation loss, and is validated empirically on both linear models and deep neural networks.