Towards Video Text Visual Question Answering: Benchmark and Baseline
{kind=link}
Abstract
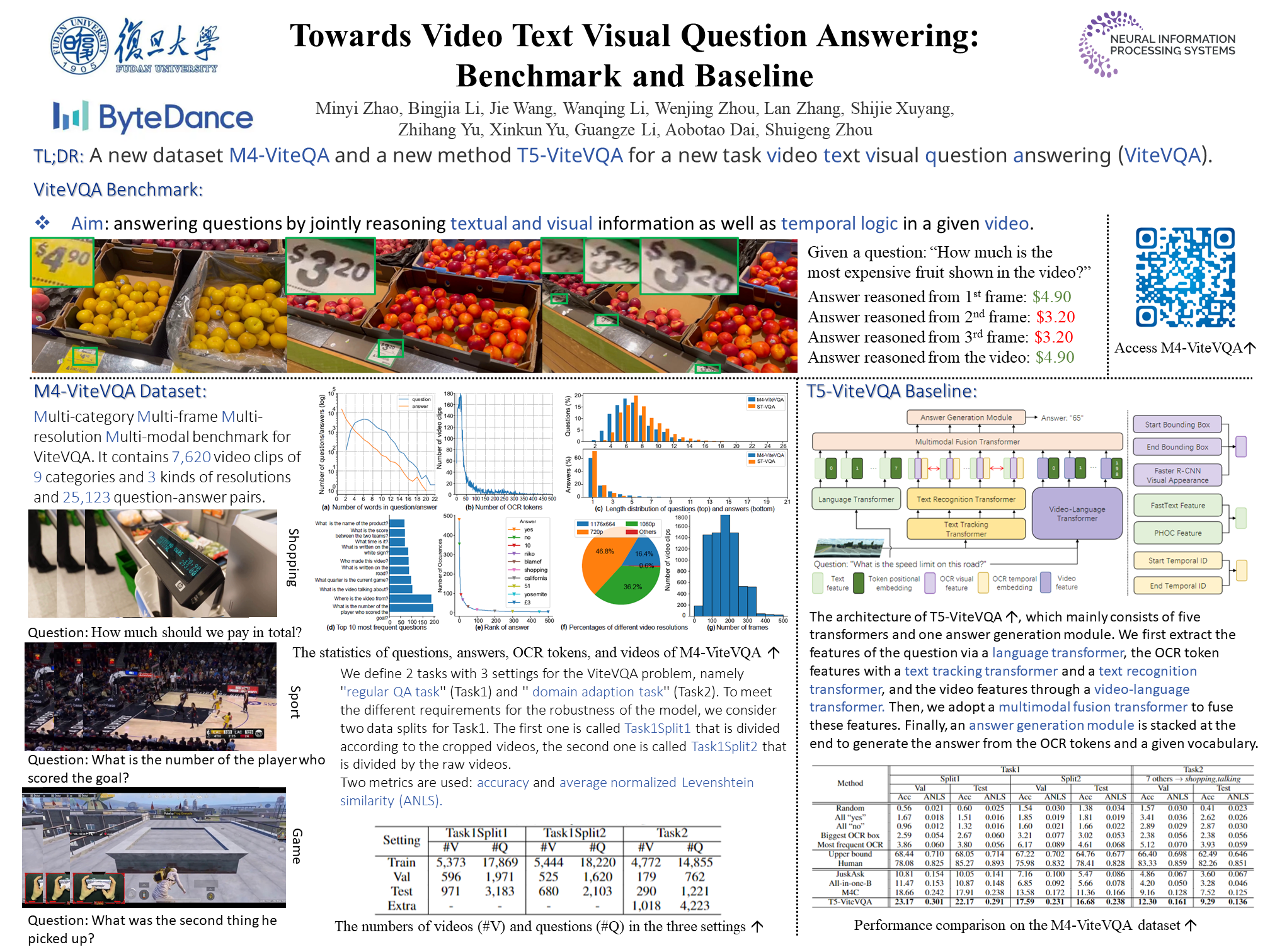
There are already some text-based visual question answering (TextVQA) benchmarks for developing machine's ability to answer questions based on texts in images in recent years. However, models developed on these benchmarks cannot work effectively in many real-life scenarios (e.g. traffic monitoring, shopping ads and e-learning videos) where temporal reasoning ability is required. To this end, we propose a new task named Video Text Visual Question Answering (ViteVQA in short) that aims at answering questions by reasoning texts and visual information spatiotemporally in a given video. In particular, on the one hand, we build the first ViteVQA benchmark dataset named M4-ViteVQA --- the abbreviation of Multi-category Multi-frame Multi-resolution Multi-modal benchmark for ViteVQA, which contains 7,620 video clips of 9 categories (i.e., shopping, traveling, driving, vlog, sport, advertisement, movie, game and talking) and 3 kinds of resolutions (i.e., 720p, 1080p and 1176x664), and 25,123 question-answer pairs. On the other hand, we develop a baseline method named T5-ViteVQA for the ViteVQA task. T5-ViteVQA consists of five transformers. It first extracts optical character recognition (OCR) tokens, question features, and video representations via two OCR transformers, one language transformer and one video-language transformer, respectively. Then, a multimodal fusion transformer and an answer generation module are applied to fuse multimodal information and generate the final prediction. Extensive experiments on M4-ViteVQA demonstrate the superiority of T5-ViteVQA to the existing approaches of TextVQA and VQA tasks. The ViteVQA benchmark is available in https://github.com/bytedance/VTVQA.