Matryoshka Representation Learning
Aditya Kusupati ⋅ Gantavya Bhatt ⋅ Aniket Rege ⋅ Matthew Wallingford ⋅ Aditya Sinha ⋅ Vivek Ramanujan ⋅ William Howard-Snyder ⋅ Kaifeng Chen ⋅ Sham Kakade ⋅ Prateek Jain ⋅ Ali Farhadi
Keywords:
Deep Learning
Representation Learning
Large-scale Retrieval
Large-scale Classification
Computer Vision
Efficient Deployment
2022 Poster
{kind=link}
Abstract
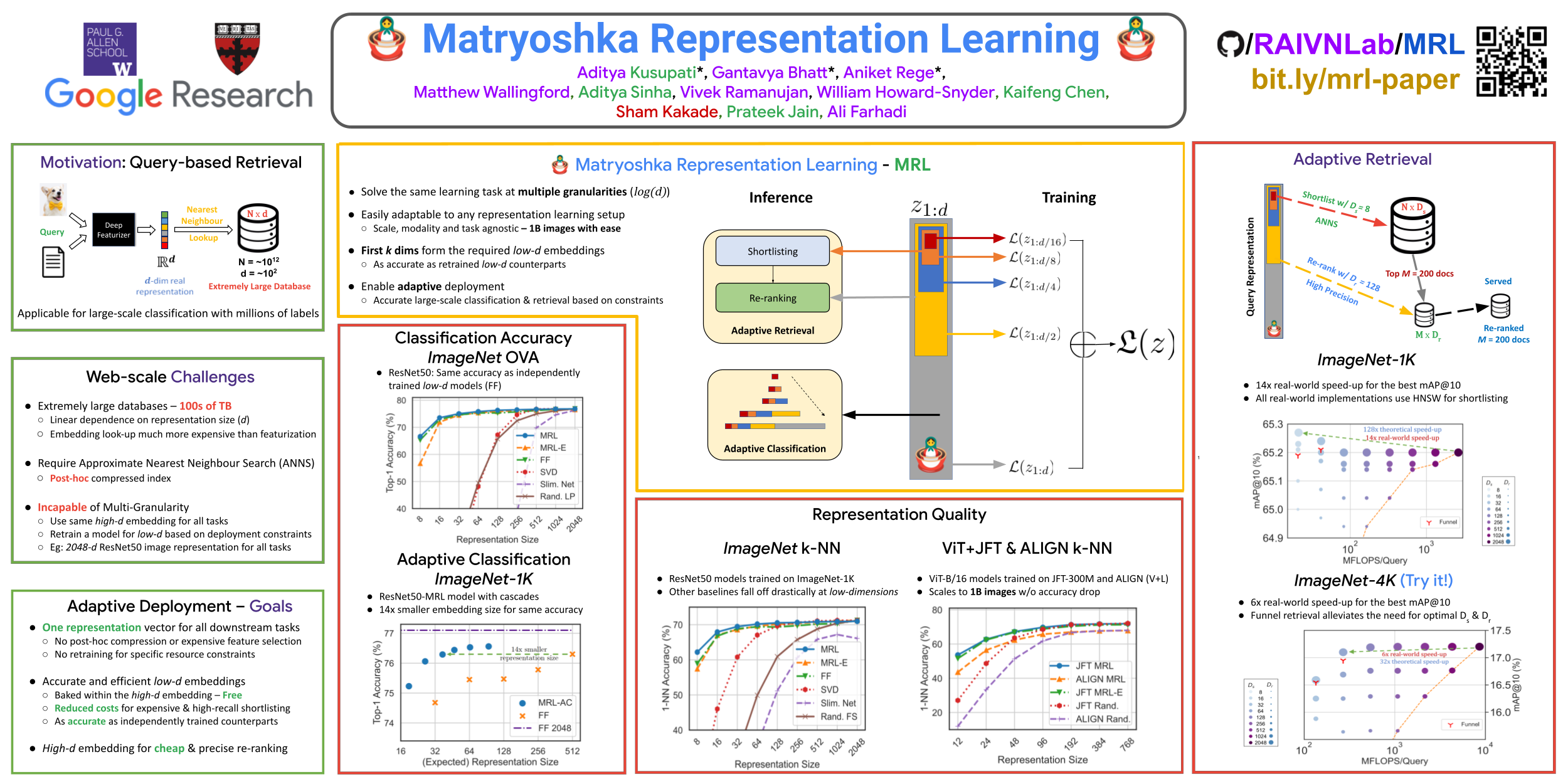
Learned representations are a central component in modern ML systems, serving a multitude of downstream tasks. When training such representations, it is often the case that computational and statistical constraints for each downstream task are unknown. In this context rigid, fixed capacity representations can be either over or under-accommodating to the task at hand. This leads us to ask: can we design a flexible representation that can adapt to multiple downstream tasks with varying computational resources? Our main contribution is Matryoshka Representation Learning (MRL) which encodes information at different granularities and allows a single embedding to adapt to the computational constraints of downstream tasks. MRL minimally modifies existing representation learning pipelines and imposes no additional cost during inference and deployment. MRL learns coarse-to-fine representations that are at least as accurate and rich as independently trained low-dimensional representations. The flexibility within the learned Matryoshka Representations offer: (a) up to $\mathbf{14}\times$ smaller embedding size for ImageNet-1K classification at the same level of accuracy; (b) up to $\mathbf{14}\times$ real-world speed-ups for large-scale retrieval on ImageNet-1K and 4K; and (c) up to $\mathbf{2}\%$ accuracy improvements for long-tail few-shot classification, all while being as robust as the original representations. Finally, we show that MRL extends seamlessly to web-scale datasets (ImageNet, JFT) across various modalities -- vision (ViT, ResNet), vision + language (ALIGN) and language (BERT). MRL code and pretrained models are open-sourced at https://github.com/RAIVNLab/MRL.
Video
Chat is not available.
Successful Page Load