Most Activation Functions Can Win the Lottery Without Excessive Depth
{kind=link}
Abstract
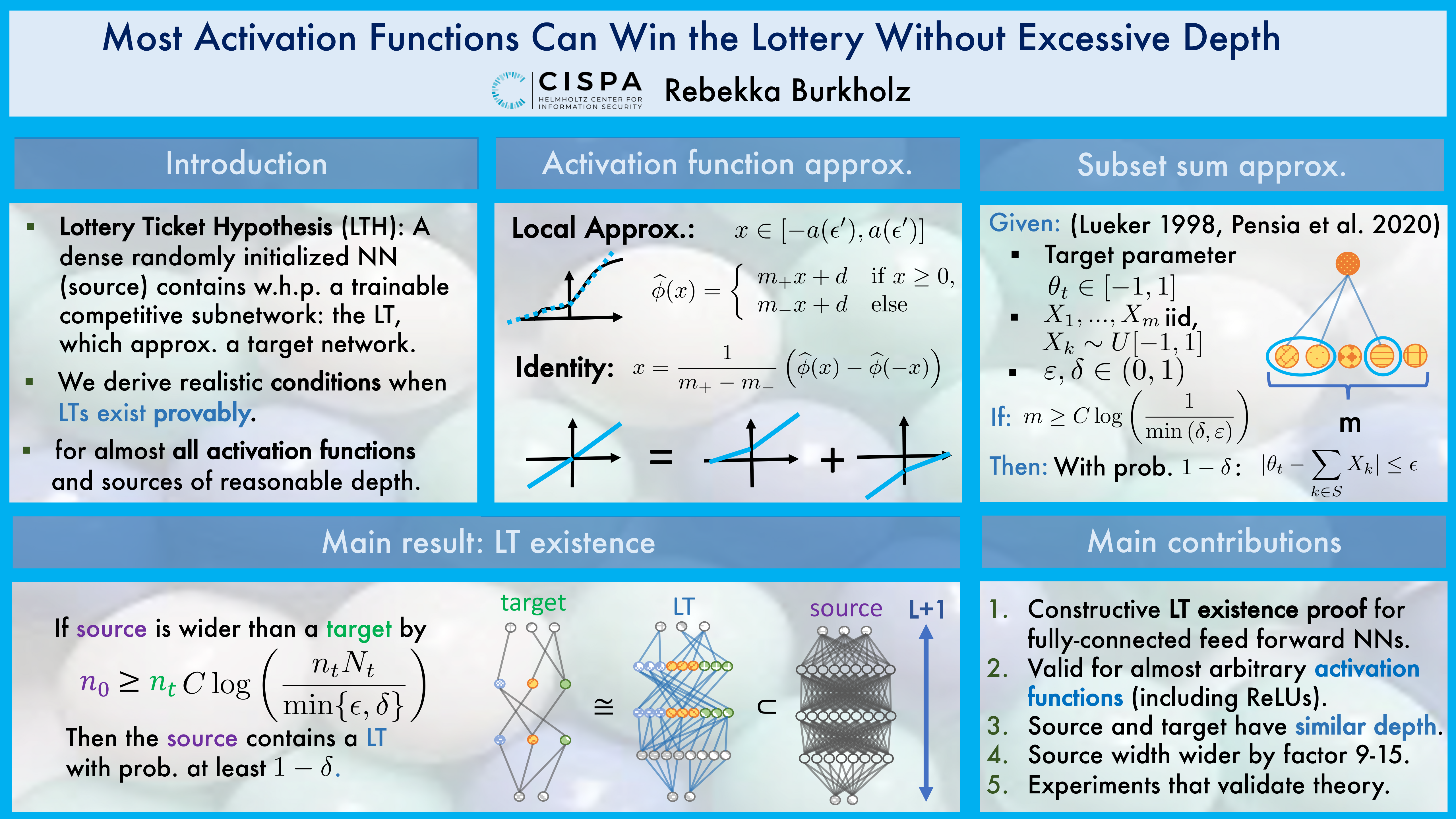
The strong lottery ticket hypothesis has highlighted the potential for training deep neural networks by pruning, which has inspired interesting practical and theoretical insights into how neural networks can represent functions. For networks with ReLU activation functions, it has been proven that a target network with depth L can be approximated by the subnetwork of a randomly initialized neural network that has double the target's depth 2L and is wider by a logarithmic factor. We show that a depth L+1 is sufficient. This result indicates that we can expect to find lottery tickets at realistic, commonly used depths while only requiring logarithmic overparametrization. Our novel construction approach applies to a large class of activation functions and is not limited to ReLUs. Code is available on Github (RelationalML/LT-existence).