A Differentiable Semantic Metric Approximation in Probabilistic Embedding for Cross-Modal Retrieval
{kind=link}
Abstract
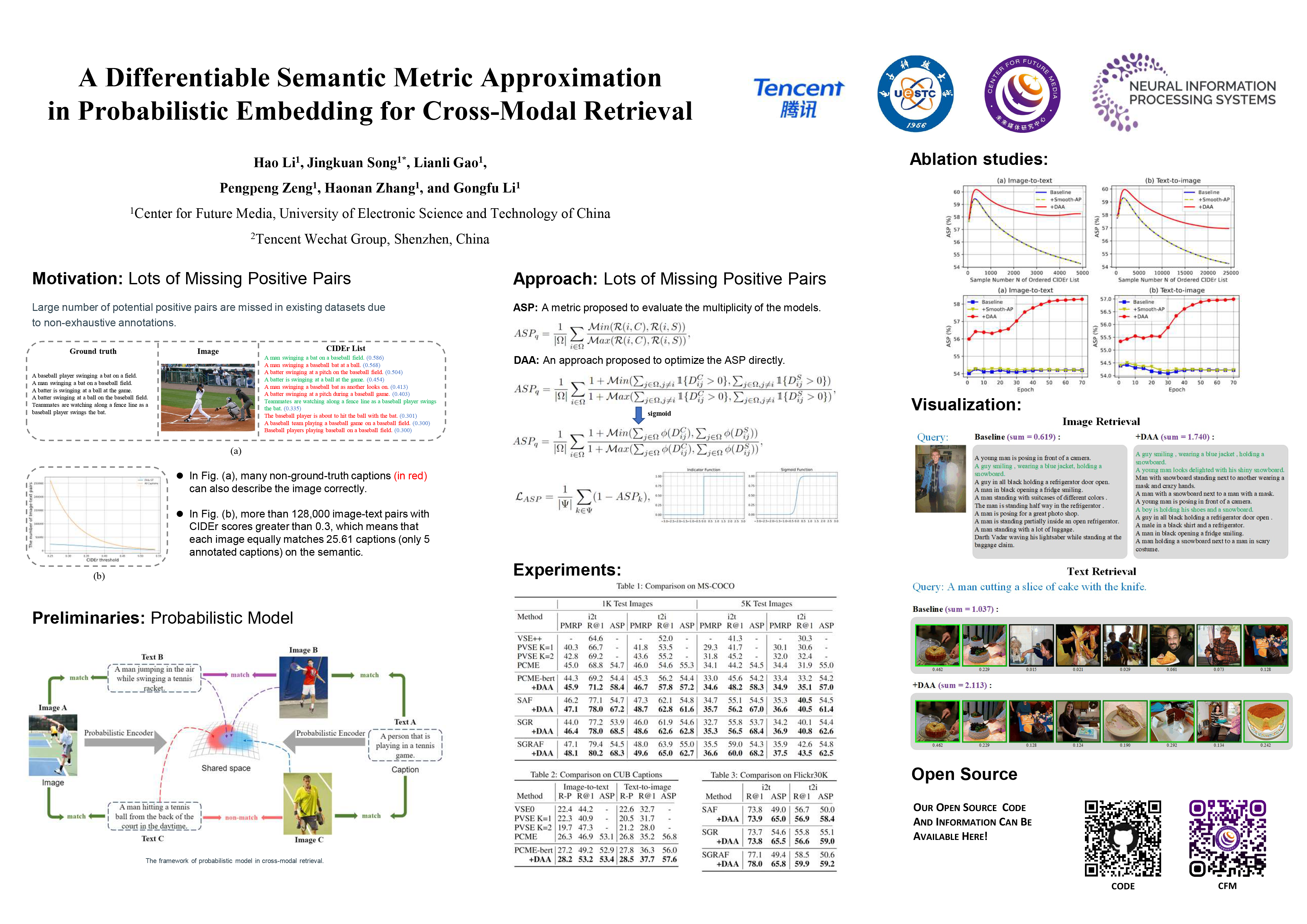
Cross-modal retrieval aims to build correspondence between multiple modalities by learning a common representation space. Typically, an image can match multiple texts semantically and vice versa, which significantly increases the difficulty of this task. To address this problem, probabilistic embedding is proposed to quantify these many-to-many relationships. However, existing datasets (e.g., MS-COCO) and metrics (e.g., Recall@K) cannot fully represent these diversity correspondences due to non-exhaustive annotations. Based on this observation, we utilize semantic correlation computed by CIDEr to find the potential correspondences. Then we present an effective metric, named Average Semantic Precision (ASP), which can measure the ranking precision of semantic correlation for retrieval sets. Additionally, we introduce a novel and concise objective, coined Differentiable ASP Approximation (DAA). Concretely, DAA can optimize ASP directly by making the ranking function of ASP differentiable through a sigmoid function. To verify the effectiveness of our approach, extensive experiments are conducted on MS-COCO, CUB Captions, and Flickr30K, which are commonly used in cross-modal retrieval. The results show that our approach obtains superior performance over the state-of-the-art approaches on all metrics. The code and trained models are released at https://github.com/leolee99/2022-NeurIPS-DAA.