Near-Optimal Private and Scalable $k$-Clustering
Vincent Cohen-Addad ⋅ Alessandro Epasto ⋅ Vahab Mirrokni ⋅ Shyam Narayanan ⋅ Peilin Zhong
2022 Poster
{kind=link}
Abstract
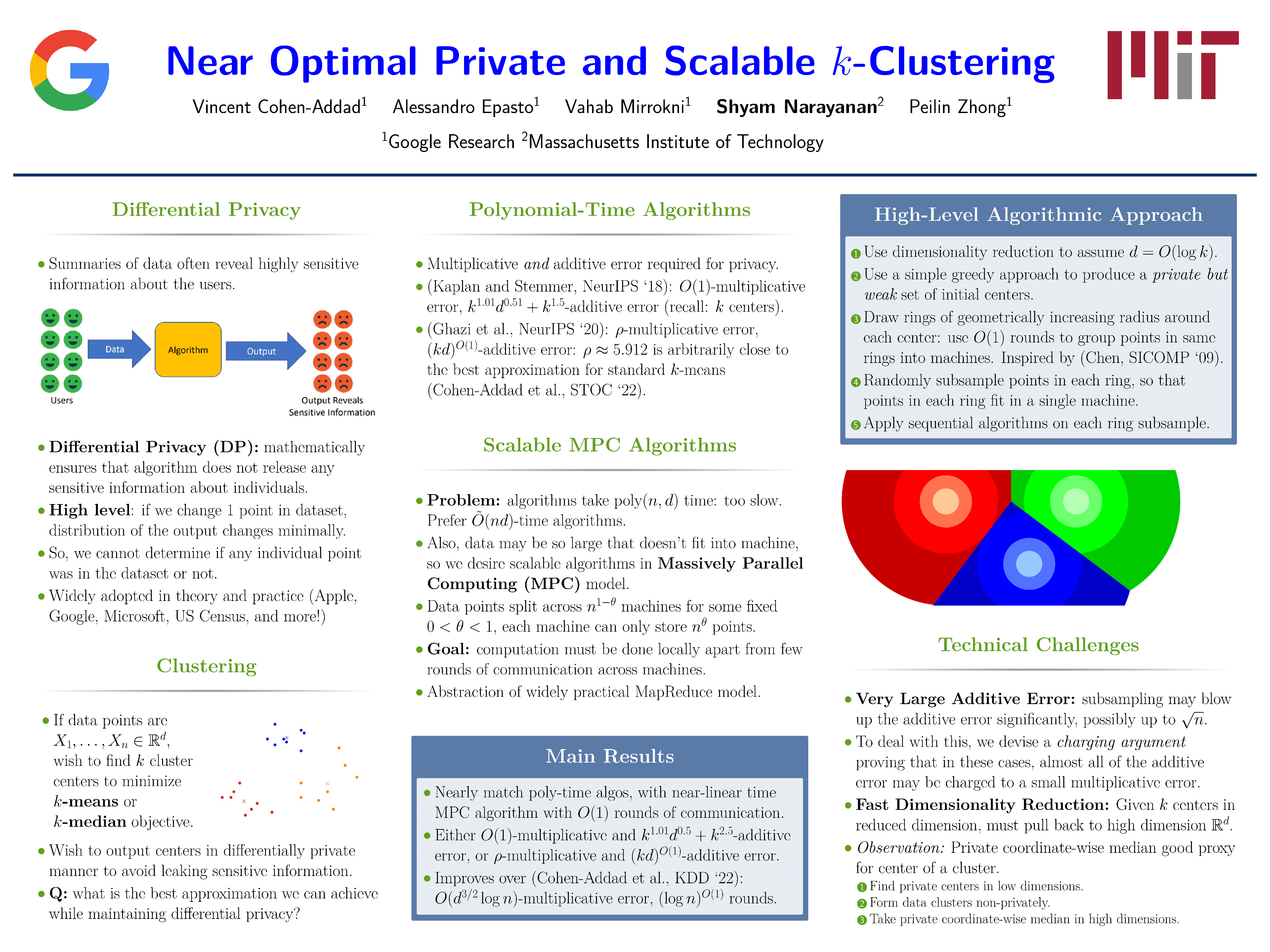
We study the differentially private (DP) $k$-means and $k$-median clustering problems of $n$ points in $d$-dimensional Euclidean space in the massively parallel computation (MPC) model. We provide two near-optimal algorithms where the near-optimality is in three aspects: they both achieve (1). $O(1)$ parallel computation rounds, (2). near-linear in $n$ and polynomial in $k$ total computational work (i.e., near-linear running time when $n$ is a sufficient polynomial in $k$), (3). $O(1)$ relative approximation and $\text{poly}(k, d)$ additive error. Note that $\Omega(1)$ relative approximation is provably necessary even for any polynomial-time non-private algorithm, and $\Omega(k)$ additive error is a provable lower bound for any polynomial-time DP $k$-means/median algorithm. Our two algorithms provide a tradeoff between the relative approximation and the additive error: the first has $O(1)$ relative approximation and $\sim (k^{2.5} + k^{1.01} \sqrt{d})$ additive error, and the second one achieves $(1+\gamma)$ relative approximation to the optimal non-private algorithm for an arbitrary small constant $\gamma>0$ and with $\text{poly}(k, d)$ additive error for a larger polynomial dependence on $k$ and $d$. To achieve our result, we develop a general framework which partitions the data and reduces the DP clustering problem for the entire dataset to the DP clustering problem for each part. To control the blow-up of the additive error introduced by each part, we develop a novel charging argument which might be of independent interest.
Video
Chat is not available.
Successful Page Load