Offline Goal-Conditioned Reinforcement Learning via $f$-Advantage Regression
Jason Yecheng Ma ⋅ Jason Yan ⋅ Dinesh Jayaraman ⋅ Osbert Bastani
Keywords:
Deep Reinforcement Learning
offline reinforcement learning
goal-conditioned reinforcement learning
2022 Poster
{kind=link}
Abstract
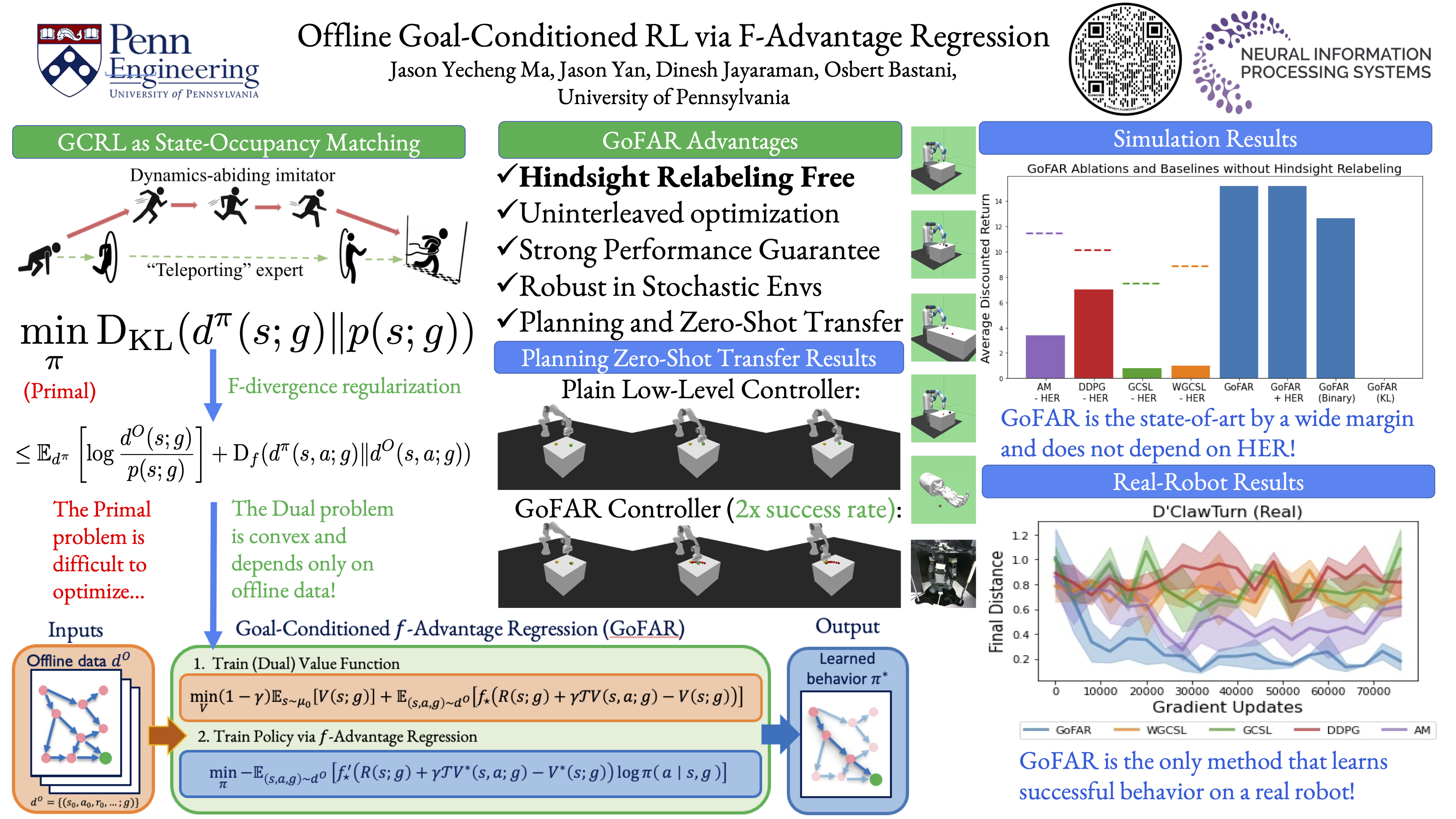
Offline goal-conditioned reinforcement learning (GCRL) promises general-purpose skill learning in the form of reaching diverse goals from purely offline datasets. We propose $\textbf{Go}$al-conditioned $f$-$\textbf{A}$dvantage $\textbf{R}$egression (GoFAR), a novel regression-based offline GCRL algorithm derived from a state-occupancy matching perspective; the key intuition is that the goal-reaching task can be formulated as a state-occupancy matching problem between a dynamics-abiding imitator agent and an expert agent that directly teleports to the goal. In contrast to prior approaches, GoFAR does not require any hindsight relabeling and enjoys uninterleaved optimization for its value and policy networks. These distinct features confer GoFAR with much better offline performance and stability as well as statistical performance guarantee that is unattainable for prior methods. Furthermore, we demonstrate that GoFAR's training objectives can be re-purposed to learn an agent-independent goal-conditioned planner from purely offline source-domain data, which enables zero-shot transfer to new target domains. Through extensive experiments, we validate GoFAR's effectiveness in various problem settings and tasks, significantly outperforming prior state-of-art. Notably, on a real robotic dexterous manipulation task, while no other method makes meaningful progress, GoFAR acquires complex manipulation behavior that successfully accomplishes diverse goals.
Video
Chat is not available.
Successful Page Load