Weighted Distillation with Unlabeled Examples
{kind=link}
Abstract
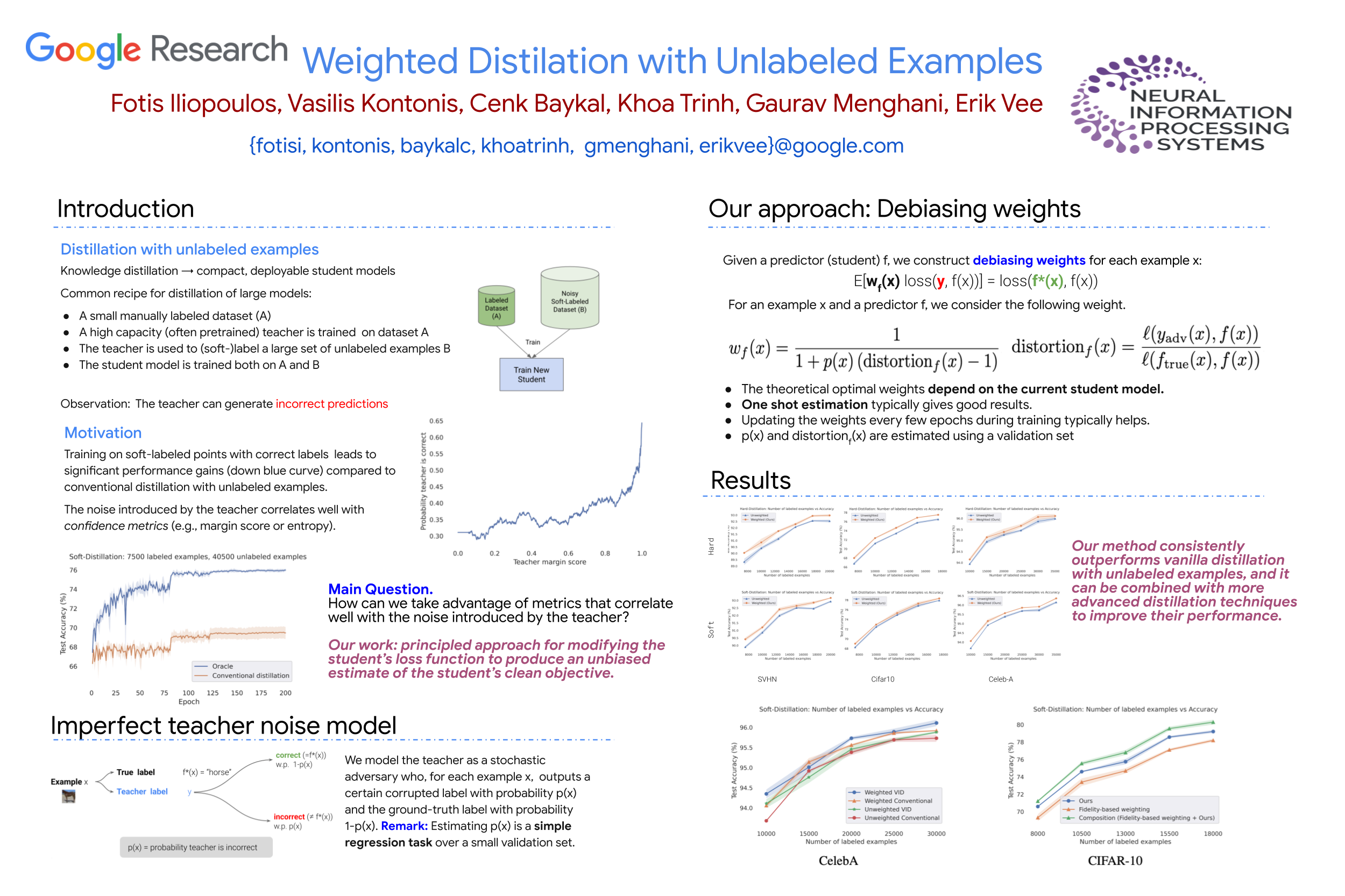
Distillation with unlabeled examples is a popular and powerful method for training deep neural networks in settings where the amount of labeled data is limited: A large “teacher” neural network is trained on the labeled data available, and then it is used to generate labels on an unlabeled dataset (typically much larger in size). These labels are then utilized to train the smaller “student” model which will actually be deployed. Naturally, the success of the approach depends on the quality of the teacher’s labels, since the student could be confused if trained on inaccurate data. This paper proposes a principled approach for addressing this issue based on a “debiasing" reweighting of the student’s loss function tailored to the distillation training paradigm. Our method is hyper-parameter free, data-agnostic, and simple to implement. We demonstrate significant improvements on popular academic datasets and we accompany our results with a theoretical analysis which rigorously justifies the performance of our method in certain settings.