Masked Autoencoding for Scalable and Generalizable Decision Making
{kind=link}
Abstract
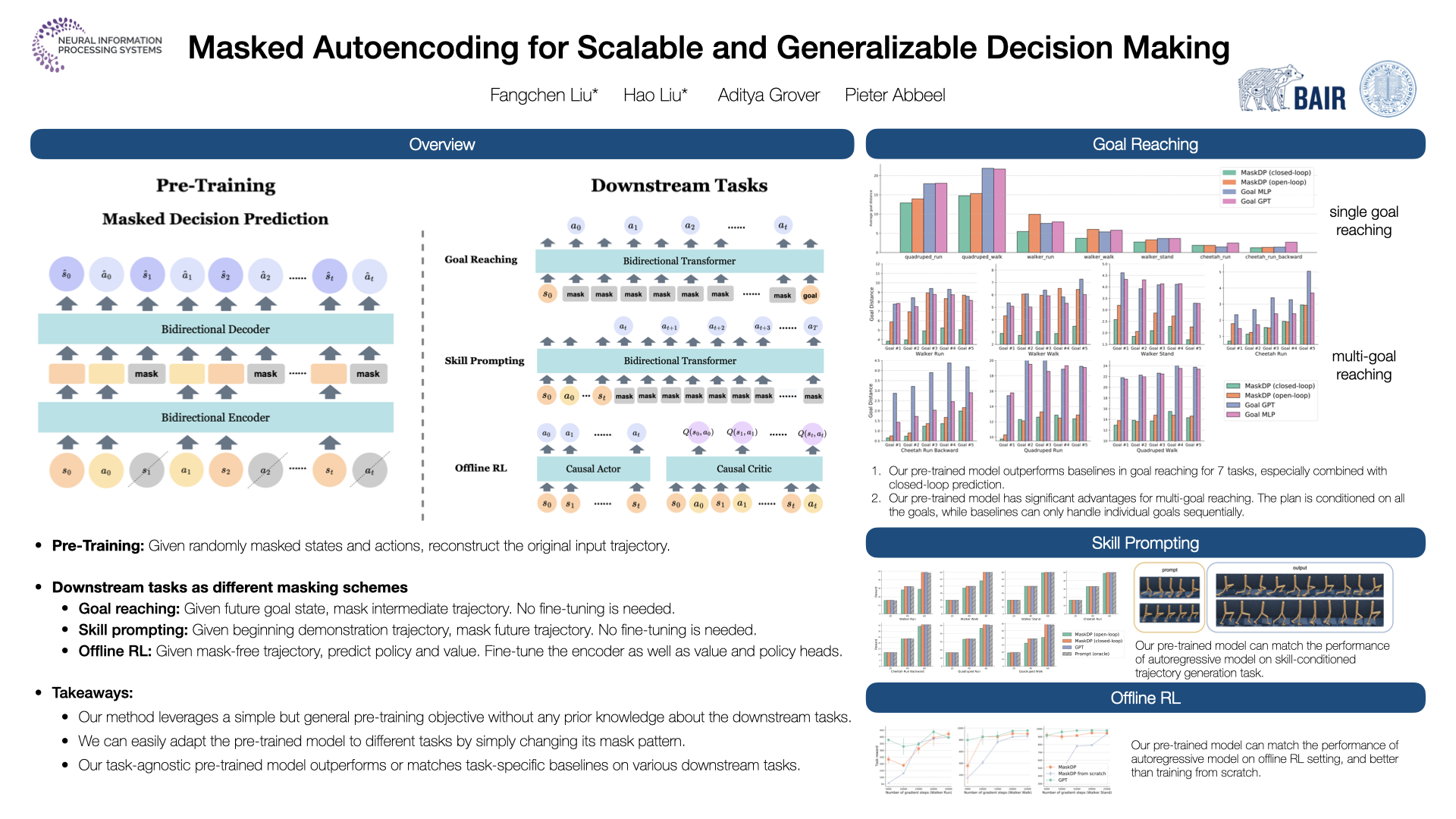
We are interested in learning scalable agents for reinforcement learning that can learn from large-scale, diverse sequential data similar to current large vision and language models. To this end, this paper presents masked decision prediction (MaskDP), a simple and scalable self-supervised pretraining method for reinforcement learning (RL) and behavioral cloning (BC). In our MaskDP approach, we employ a masked autoencoder (MAE) to state-action trajectories, wherein we randomly mask state and action tokens and reconstruct the missing data. By doing so, the model is required to infer masked out states and actions and extract information about dynamics. We find that masking different proportions of the input sequence significantly helps with learning a better model that generalizes well to multiple downstream tasks. In our empirical study we find that a MaskDP model gains the capability of zero-shot transfer to new BC tasks, such as single and multiple goal reaching, and it can zero-shot infer skills from a few example transitions. In addition, MaskDP transfers well to offline RL and shows promising scaling behavior w.r.t. to model size. It is amenable to data efficient finetuning, achieving competitive results with prior methods based on autoregressive pretraining.