Relative Behavioral Attributes: Filling the Gap between Symbolic Goal Specification and Reward Learning from Human Preferences
{kind=link}
Abstract
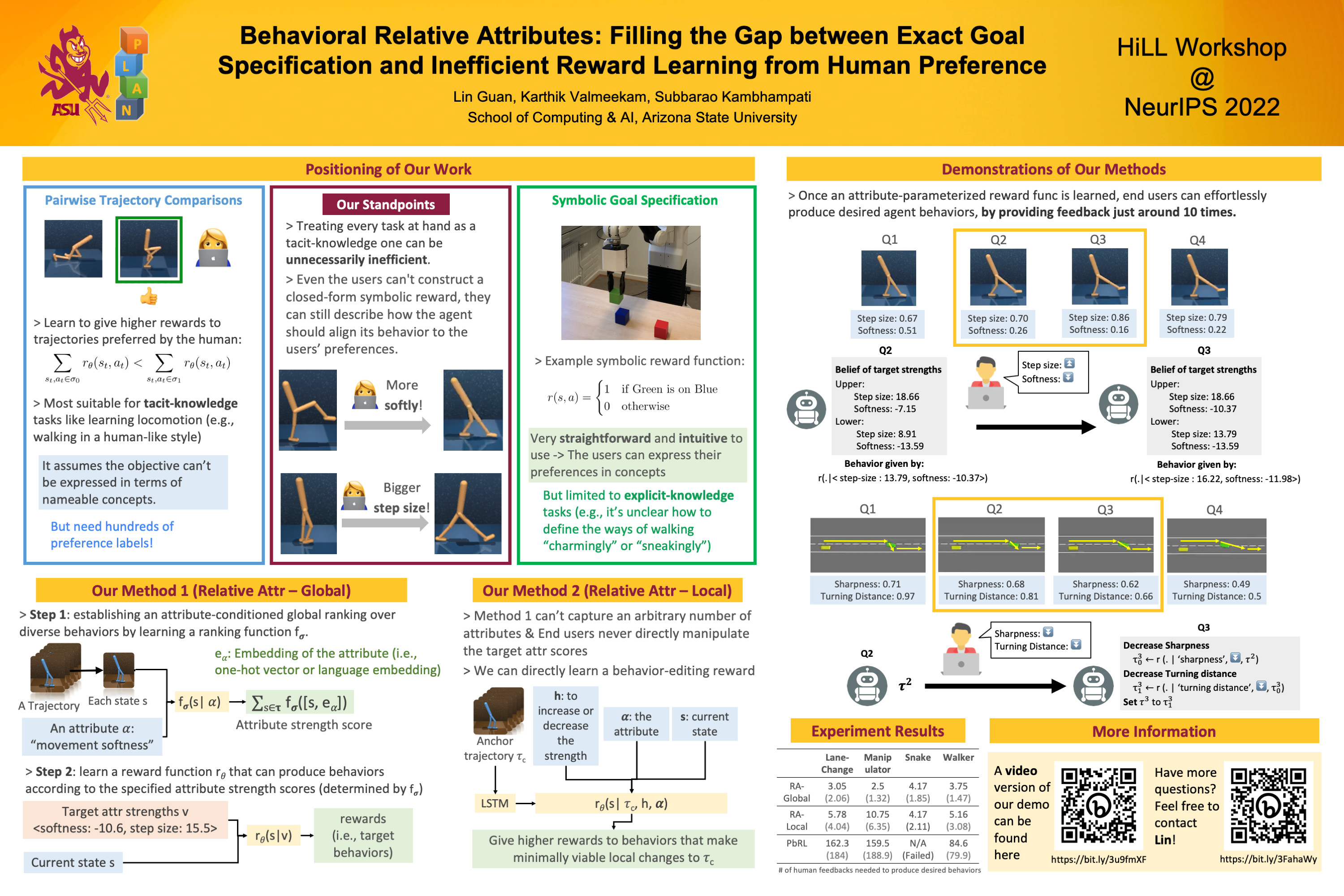
Generating complex behaviors from goals specified by non-expert users is a crucial aspect of intelligent agents. Interactive reward learning from trajectory comparisons is one way to allow non-expert users to convey complex objectives by expressing preferences over short clips of agent behaviors. Even though this method can encode complex tacit knowledge present in the underlying tasks, it implicitly assumes that the human is unable to provide rich-form feedback other than binary preference labels, leading to extremely high feedback complexity and poor user experience. While providing a detailed symbolic specification of the objectives might be tempting, it is not always feasible even for an expert user. However, in most cases, humans are aware of how the agent should change its behavior along meaningful axes to fulfill the underlying purpose, even if they are not able to fully specify task objectives symbolically. Using this as motivation, we introduce the notion of Relative Behavioral Attributes, which acts as a middle ground, between exact goal specification and reward learning purely from preference labels, by enabling the users to tweak the agent's behavior through nameable concepts (e.g., decreasing the steering sharpness of an autonomous driving agent, or increasing the softness of the movement of a two-legged "sneaky" agent). We propose two different parametric methods that can potentially encode any kind of behavioral attributes from ordered behavior clips. We demonstrate the effectiveness of our methods on 4 tasks with 9 different behavioral attributes and show that once the attributes are learned, end users can effortlessly produce desirable agent behaviors, by providing feedback just around 10 times. The feedback complexity of our approach is over 10 times less than the learning-from-human-preferences baseline and this demonstrates that our approach is readily applicable in real-world applications.