TASSAL: Task-Aware Semi-Supervised Active Learning
{kind=link}
Abstract
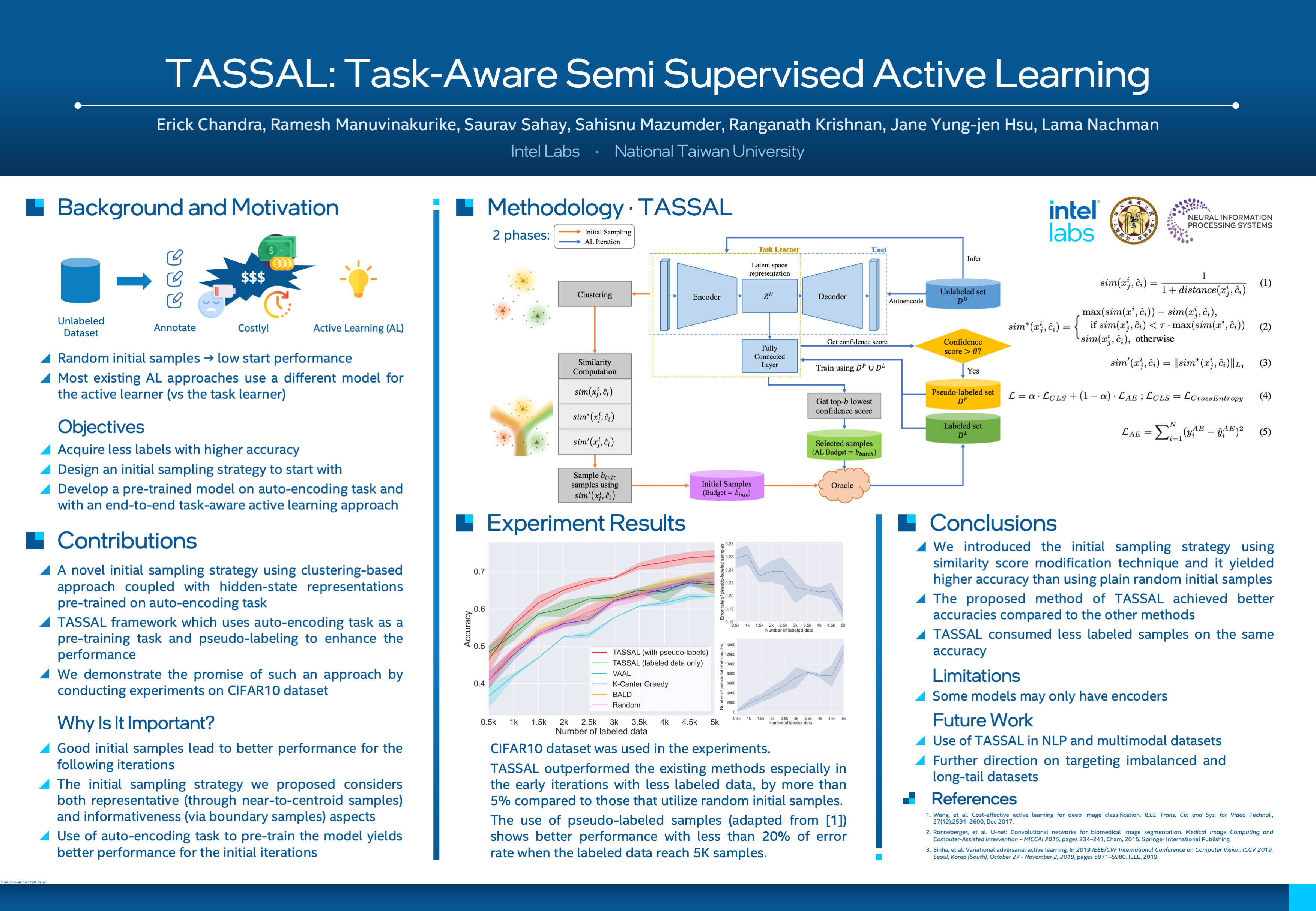
Active learning (AL) is useful for incremental model training while concurrently selecting the most informative yet minimum amount of training samples for the human annotator to label. In this paper, We introduce a pool-based efficient task-aware semi-supervised active learning (TASSAL) strategy with a modified selection probability distribution on initial sampling. In contrast to the recent approaches that separately train the core task model from the encoding models, our method allows end-to-end and simultaneous learning on both the encoding and core task model. We demonstrate that TASSAL shows a promising result and, from our experiments, it could outperform recent approaches on the CIFAR-10 dataset. In addition, evaluation of the pseudo-labeled samples against ground-truth labels shows that such an approach could potentially yield additional data to train on, which supposedly is beneficial for the downstream tasks.