Characterizing Anomalies with Explainable Classifiers
Naveen Durvasula ⋅ Valentine d Hauteville ⋅ Keegan Hines ⋅ John Dickerson
2022 Poster
in
Workshop: Challenges in Deploying and Monitoring Machine Learning Systems
in
Workshop: Challenges in Deploying and Monitoring Machine Learning Systems
{kind=link}
Abstract
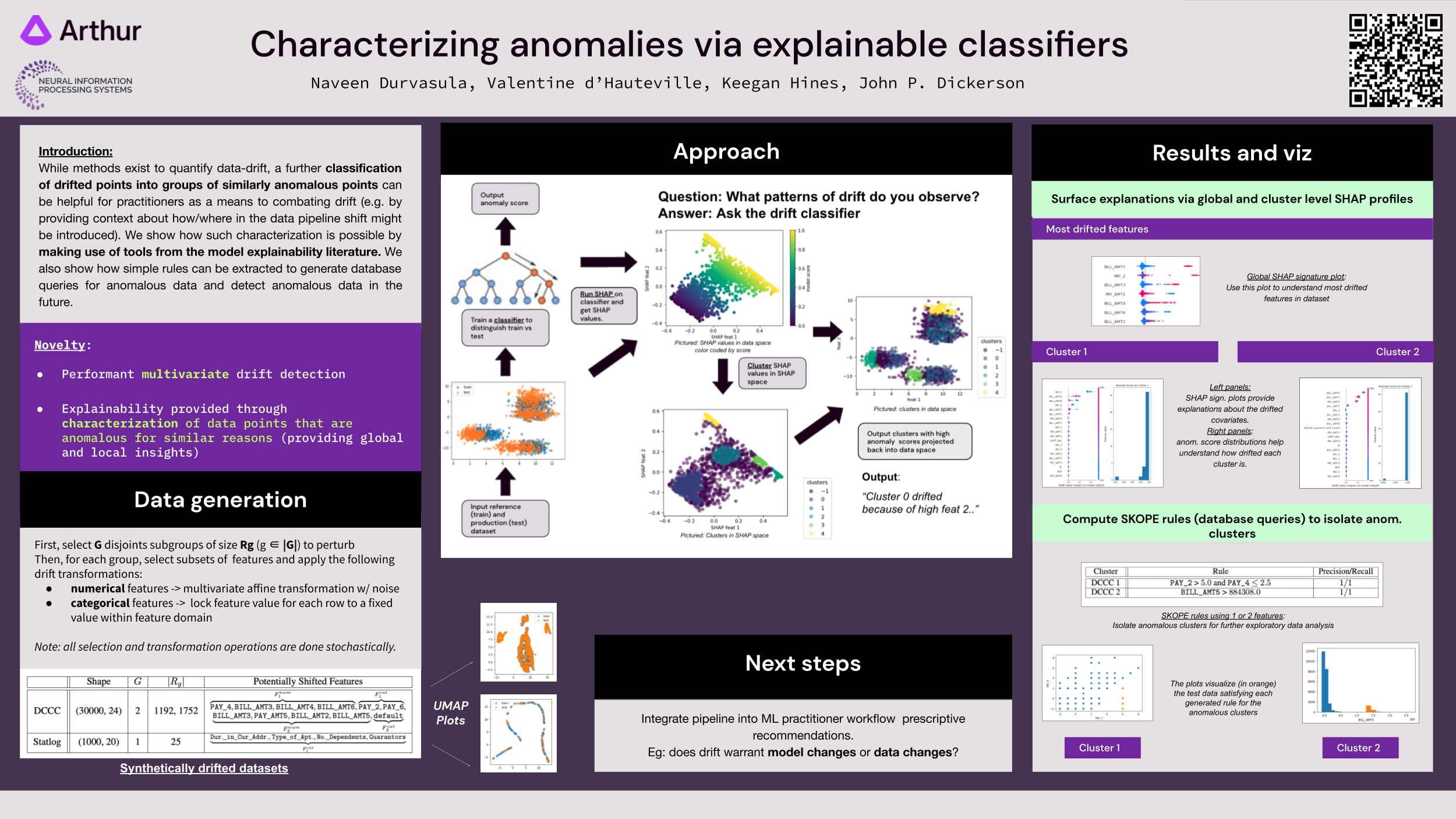
As machine learning techniques are increasingly used to make societal-scale decisions, model performance issues stemming from data-drift can result in costly consequences. While methods exist to quantify data-drift, a further classification of drifted points into groups of similarly anomalous points can be helpful for practitioners as a means to combating drift (e.g. by providing context about how/where in the data pipeline shift might be introduced). We show how such characterization is possible by making use of tools from the model explainability literature. We also show how simple rules can be extracted to generate database queries for anomalous data and detect anomalous data in the future.
Video
Chat is not available.
Successful Page Load