Bias Amplification in Image Classification
{kind=link}
Abstract
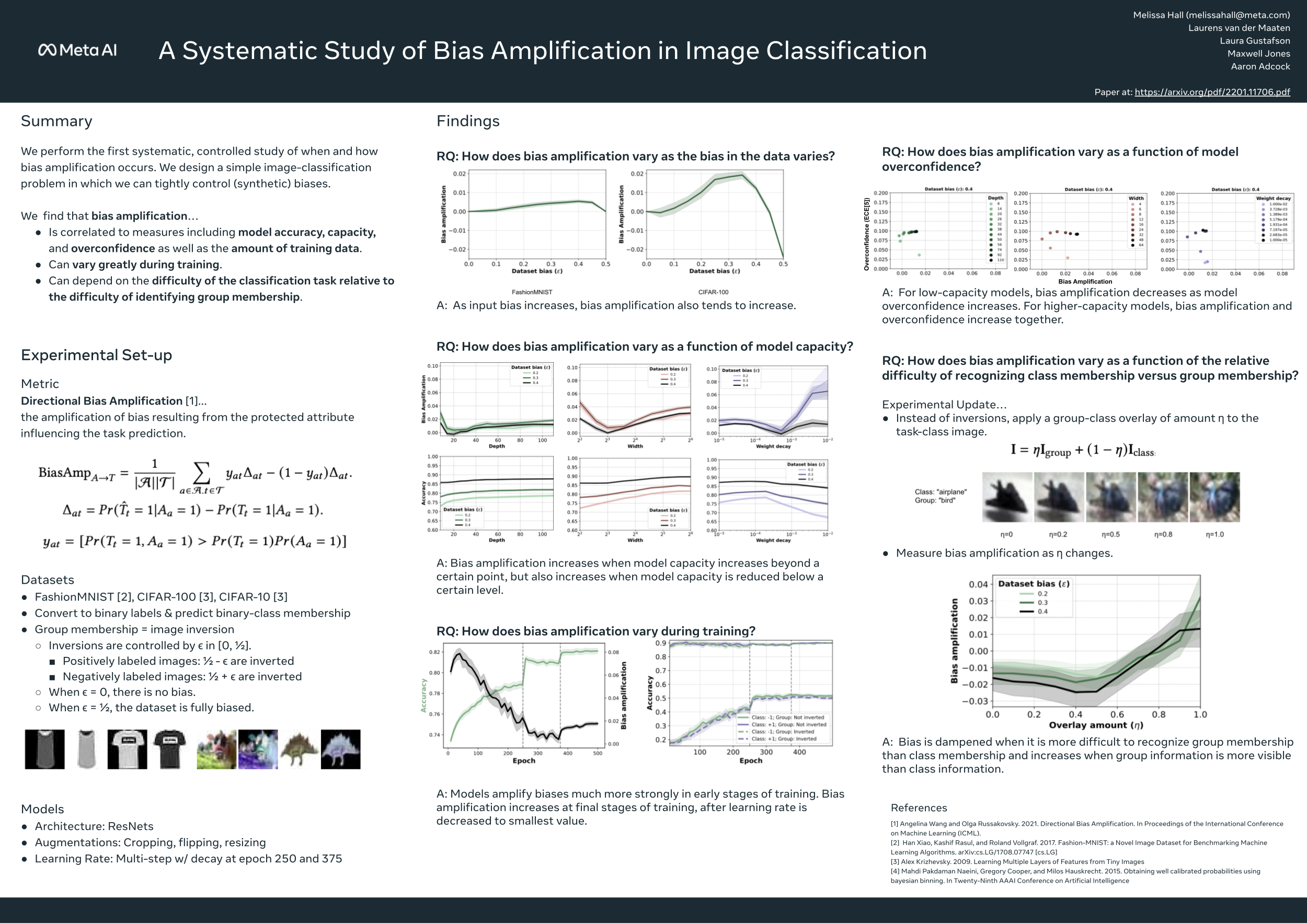
Recent research suggests that predictions made by machine-learning models can amplify biases present in the training data. Mitigating such bias amplification requires a deep understanding of the mechanics in modern machine learning that give rise to that amplification. We perform the first systematic, controlled study into when and how bias amplification occurs. To enable this study, we design a simple image-classification problem in which we can tightly control (synthetic) biases. Our study of this problem reveals that the strength of bias amplification is correlated to measures such as model accuracy, model capacity, and amount of training data. We also find that bias amplification can vary greatly during training. Finally, we find that bias amplification may depend on the difficulty of the classification task relative to the difficulty of recognizing group membership: bias amplification appears to occur primarily when it is easier to recognize group membership than class membership. Our results suggest best practices for training machine-learning models that we hope will help pave the way for the development of better mitigation strategies.