Towards Reasoning-Aware Explainable VQA
{kind=link}
Abstract
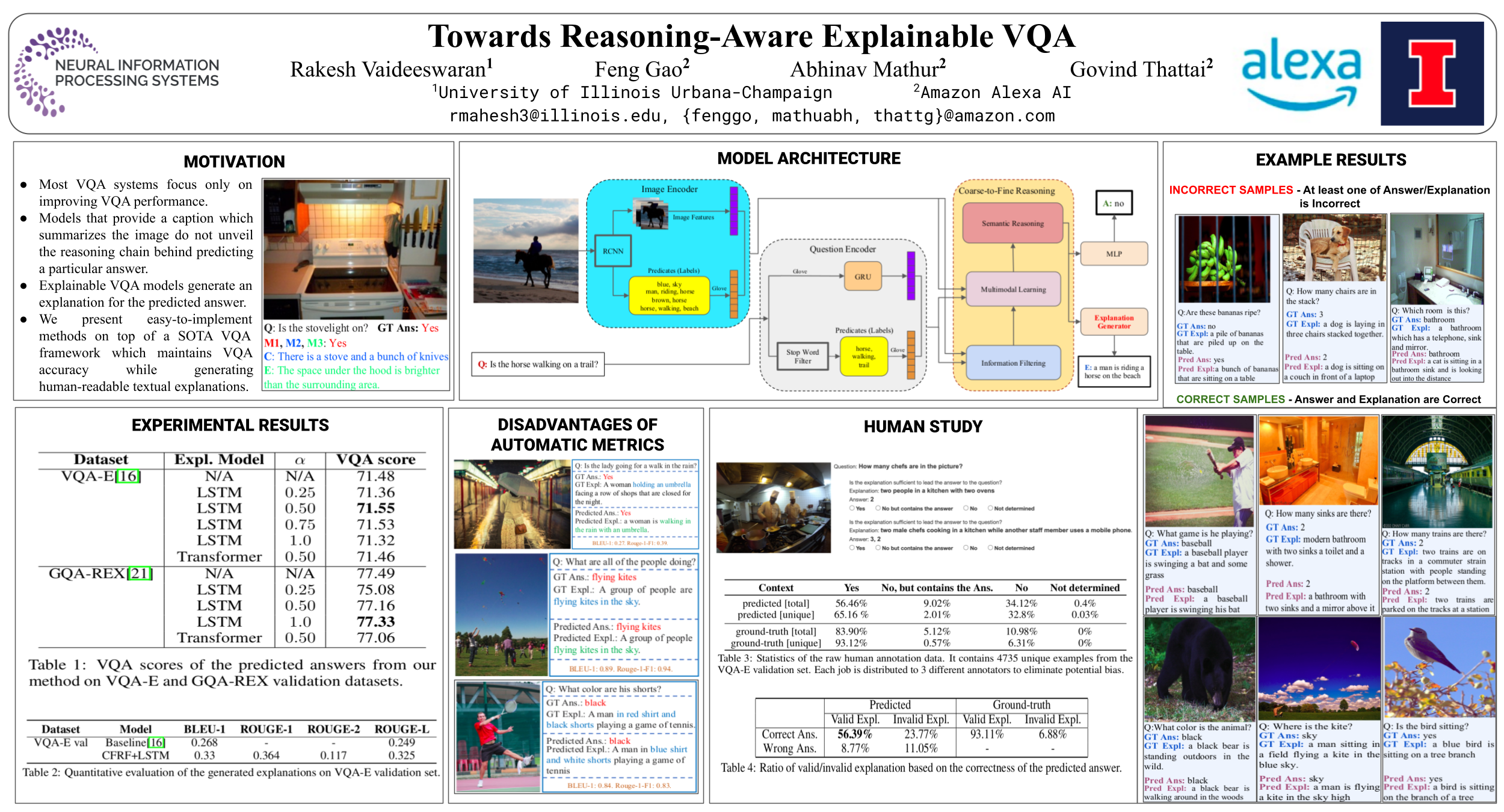
The domain of joint vision-language understanding, especially in the context of reasoning in Visual Question Answering (VQA) models, has garnered significant attention in the recent past. While most of the existing VQA models focus on improving the accuracy of VQA, the way models arrive at an answer is oftentimes a black box. As a step towards making the VQA task more explainable and interpretable, our method is built upon the SOTA VQA framework by augmenting it with an end-to-end explanation generation module. In this paper, we investigate two network architectures, including LSTM and Transformer decoder, as the explanation generator. Our method generates human-readable explanations while maintaining SOTA VQA accuracy on the GQA-REX (77.49%) and VQA-E (71.48%) datasets. Approximately 65.16% of the generated explanations are approved to be valid by humans. Roughly 60.5% of the generated explanations are valid and lead to the correct answers.