DynamicViT: Making Vision Transformer faster through layer skipping
Amanuel Mersha ⋅ Samuel Assefa
2022 [1st] Poster session
in
Workshop: Vision Transformers: Theory and applications
in
Workshop: Vision Transformers: Theory and applications
{kind=link}
Abstract
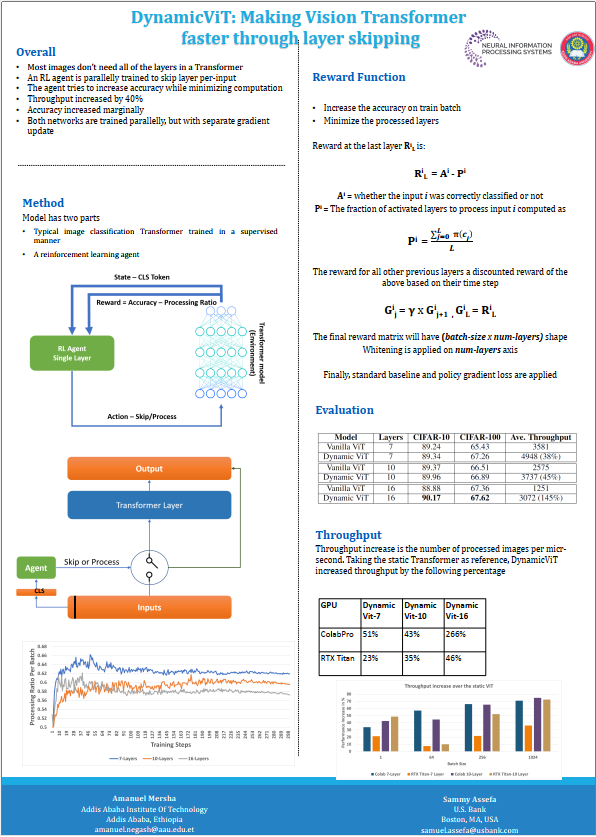
The recent deep learning breakthroughs in language and vision tasks can be mainly attributed to large-scale transformers. Unfortunately, their massive size and high compute requirement have limited their use in resource-constrained environments. Dynamic neural networks could potentially reduce the amount of compute requirement by dynamically adjusting the computational path based on the input. We propose a layer skipping dynamic transformer network that skips layers for each sample based on decisions given by a reinforcement learning agent. Extensive experiment on CIFAR-10 and CIFAR-100 showed that this dynamic ViT model gained an average of 40\% speed increase evaluated on different batch sizes ranging from 1 to 1024.
Chat is not available.
Successful Page Load