Information Bottleneck for Multi-Task LSTMs
{kind=link}
Abstract
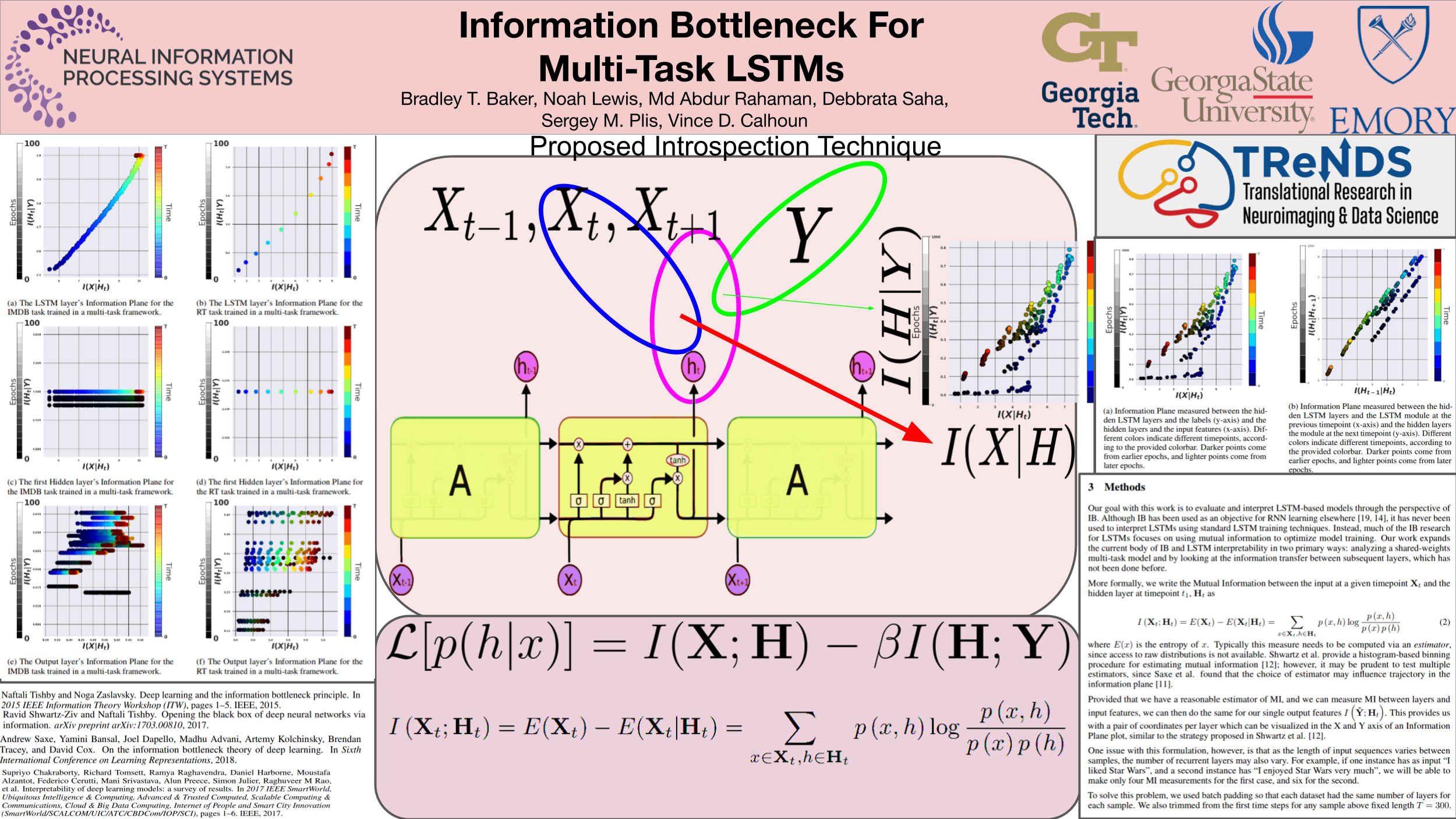
Neural networks, which have had a profound effect on how researchers , do so through a complex, nonlinear mathematical structure which can be difficult to interpret or understand. This is especially true for recurrent models, as their dynamic structure can be difficult to measure and analyze. However, interpretability is a key factor in understanding certain problems such as text and language analysis. In this paper, we present a novel introspection method for LSTMs trained to solve complex language problems, such as sentiment analysis. Inspired by Information Bottleneck theory, our method uses a state-of-the-art information theoretic framework to visualize shared information around labels, features, and between layers. We apply our approach on simulated data, and real sentiment analysis datasets, providing novel, information-theoretic insights into internal model dynamics.