PromptDA: Label-guided Data Augmentation for Prompt-based Few Shot Learners
in
Workshop: Second Workshop on Efficient Natural Language and Speech Processing (ENLSP-II)
{kind=link}
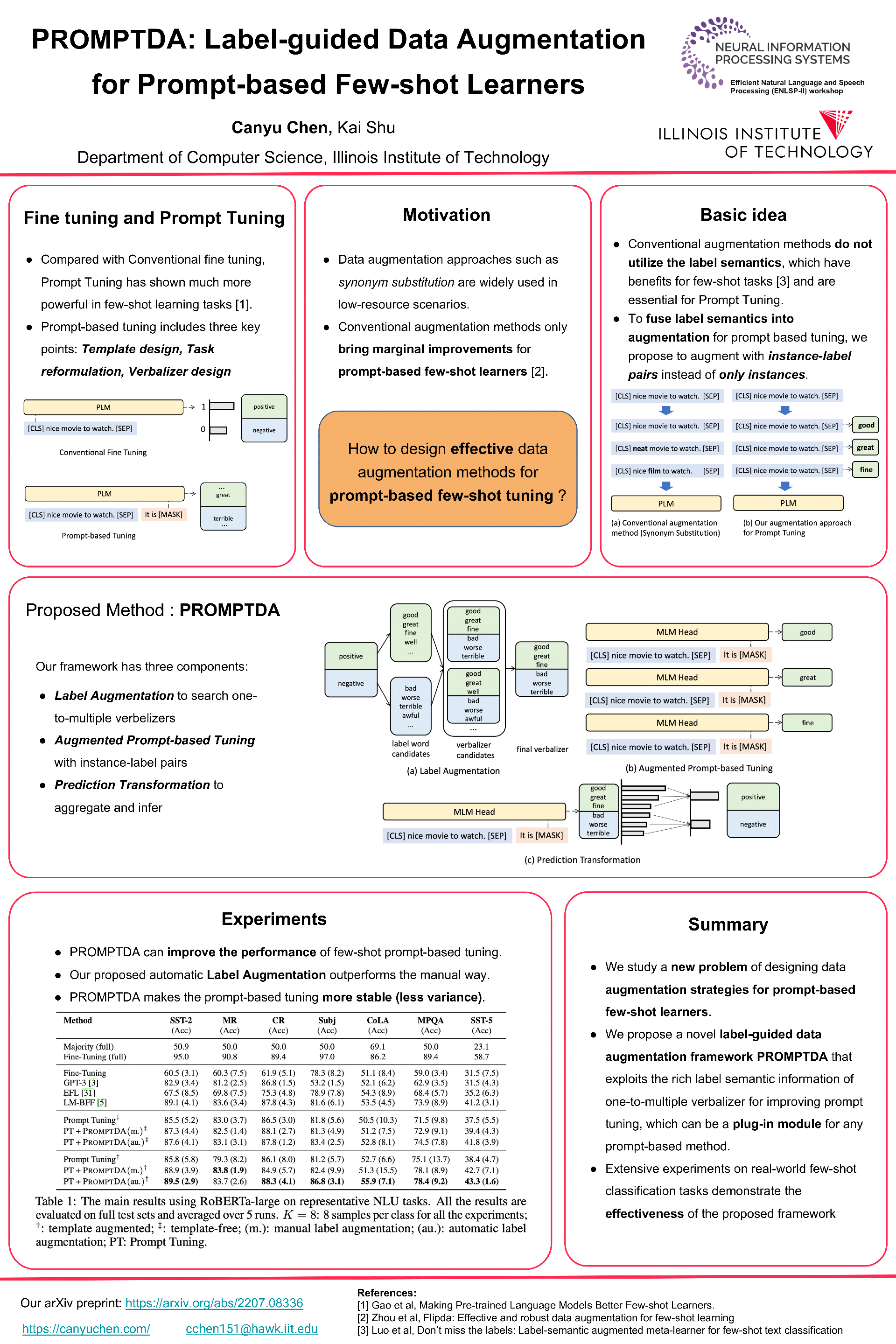
Abstract
Recent advances in large pre-trained language models (PLMs) lead to impressive gains on natural language understanding (NLU) tasks with task-specific fine-tuning. However, direct fine-tuning PLMs heavily relies on a large amount of labeled instances, which are usually hard to obtain. Prompt-based tuning on PLMs has proven valuable for various few-shot tasks. Existing works studying prompt-based tuning for few-shot NLU tasks mainly focus on deriving proper label words with a verbalizer or generating prompt templates for eliciting semantics from PLMs. In addition, conventional data augmentation methods have also been verified useful for few-shot tasks. However, currently there are few data augmentation methods designed for the prompt-based tuning paradigm. Therefore, we study a new problem of data augmentation for prompt-based few shot learners. Since the label semantics are essential in prompt-based tuning, we propose a novel label-guided data augmentation method PromptDA which exploits the enriched label semantic information for data augmentation. Extensive experiment results on few-shot text classification tasks show that our proposed framework achieves superior performance by effectively leveraging label semantics and data augmentation for natural language understanding.