Gradient Knowledge Distillation for Pre-trained Language Models
{kind=link}
Abstract
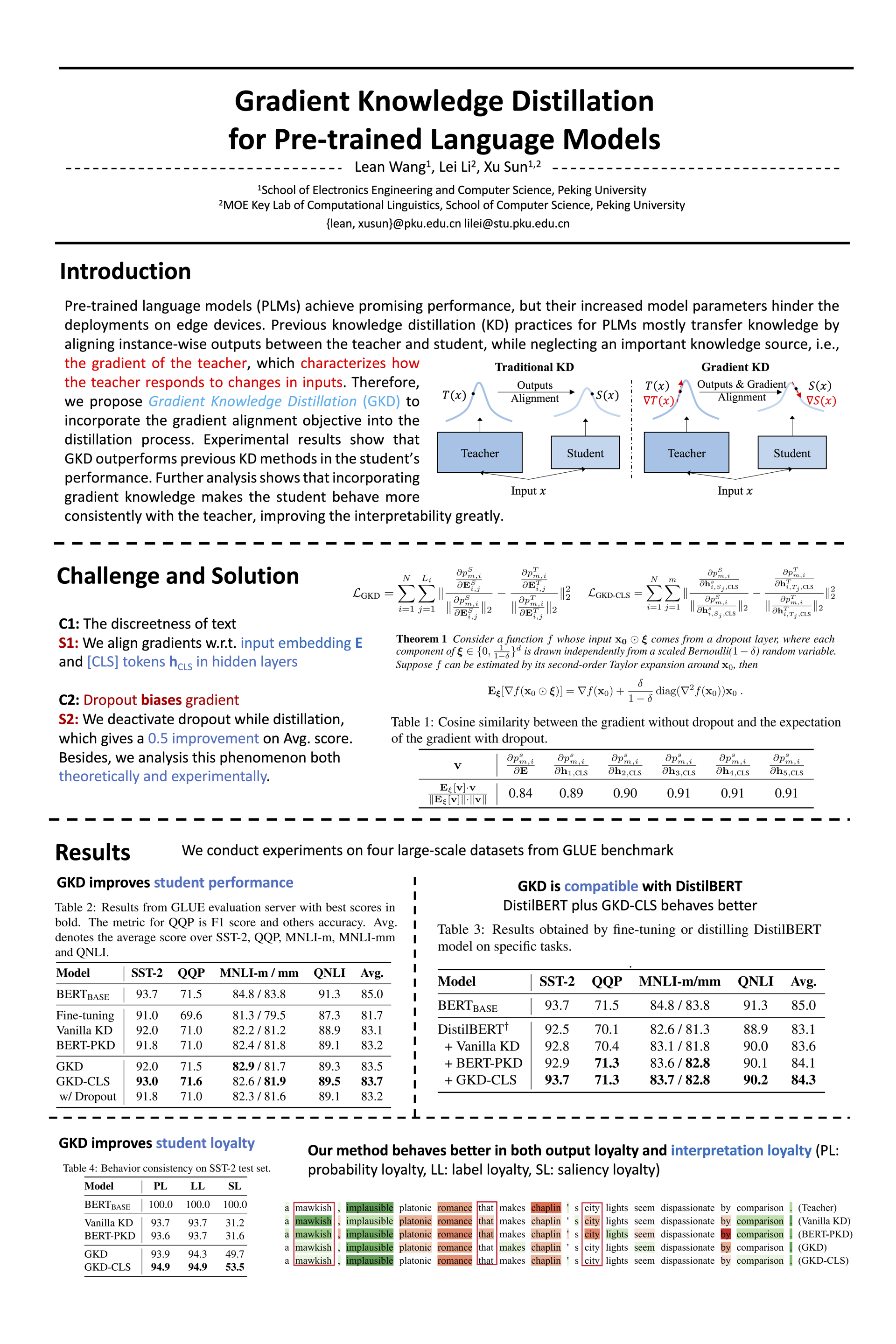
Knowledge distillation (KD) is an effective framework to transfer knowledge from a large-scale teacher to a compact yet well-performing student. Previous KD practices for pre-trained language models transfer knowledge by aligning instance-wise outputs between the teacher and the student, while neglecting an important knowledge source, i.e., the gradient of the teacher. The gradient characterizes how the teacher responds to changes in inputs, which we assume is beneficial for the student to better approximate the underlying mapping function of the teacher. Therefore, we propose Gradient Knowledge Distillation (GKD) to incorporate the gradient alignment objective into the distillation process.Experimental results show that GKD outperforms previous KD methods in the student's performance. Further analysis shows that incorporating gradient knowledge makes the student behave more consistently with the teacher, improving the interpretability greatly.