Depth-Wise Attention (DWAtt): A Layer Fusion Method for Data-Efficient Classification
{kind=link}
Abstract
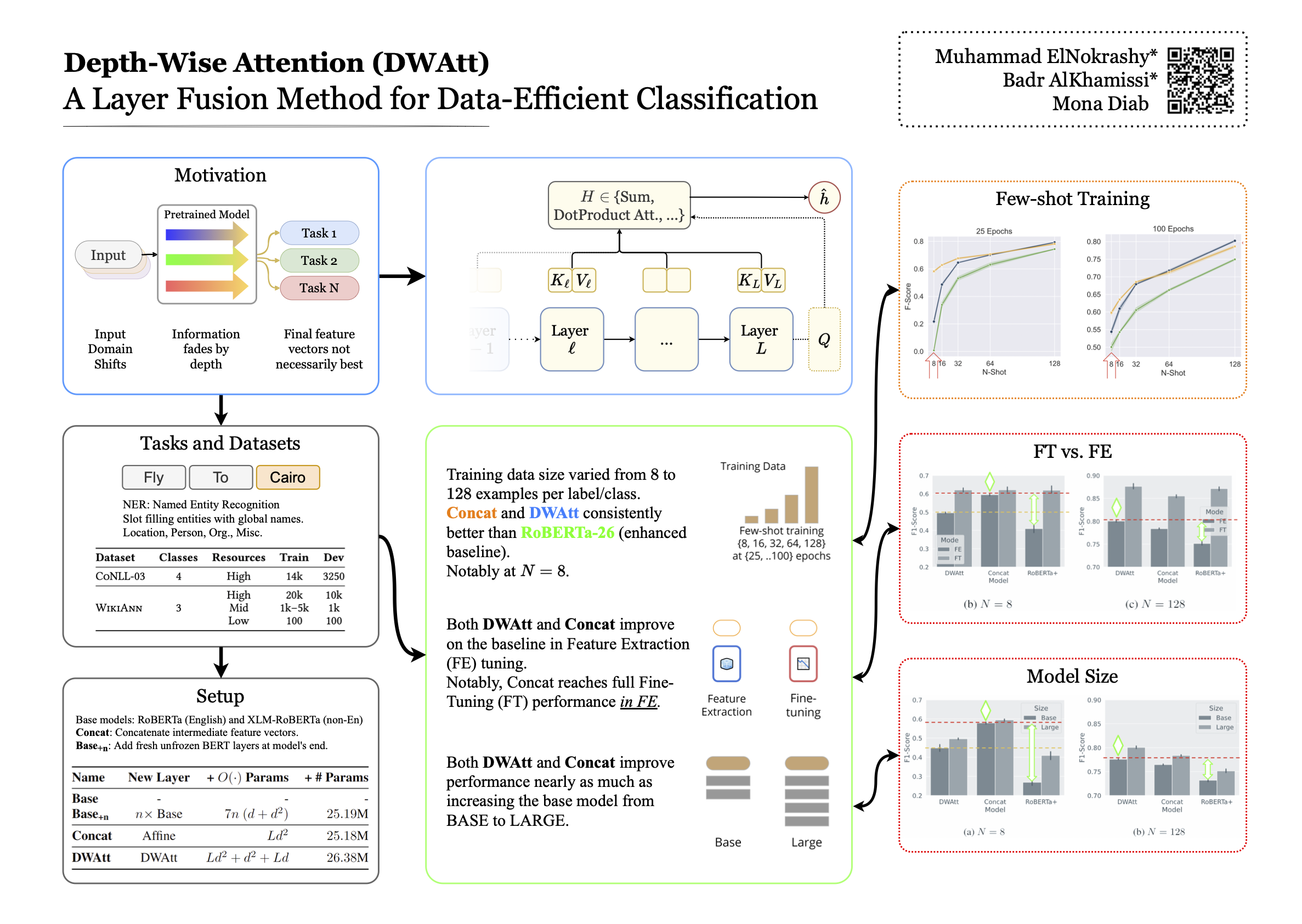
Language Models pretrained on large textual data have been shown to encode different types of knowledge simultaneously. Usually, only the features from the last layer are used when adapting to new tasks or data. We put forward that in using or finetuning deep pretrained models, intermediate layer features that may be relevant to the downstream task are buried too deep to be used efficiently in terms of needed samples or steps. To test this, we propose a new layer fusion method: Depth-Wise Attention (DWAtt), to help re-surface signals from non-final model layers. We compare DWAtt to a basic concatenation-based layer fusion method (Concat), and compare both to a deeper model baseline---all kept within a similar parameter budget. Our findings show that DWAtt and Concat are more step- and sample-efficient than the baseline, especially in the few-shot setting. DWAtt outperforms Concat on larger data sizes. On CoNLL-03 NER, layer fusion shows 3.68-9.73\% F1 gain at different few-shot sizes. The layer fusion models presented significantly outperform the baseline in various training scenarios with different data sizes, architectures, and training constraints.