ContextNER: Contextual Phrase Generation at Scale
{kind=link}
Abstract
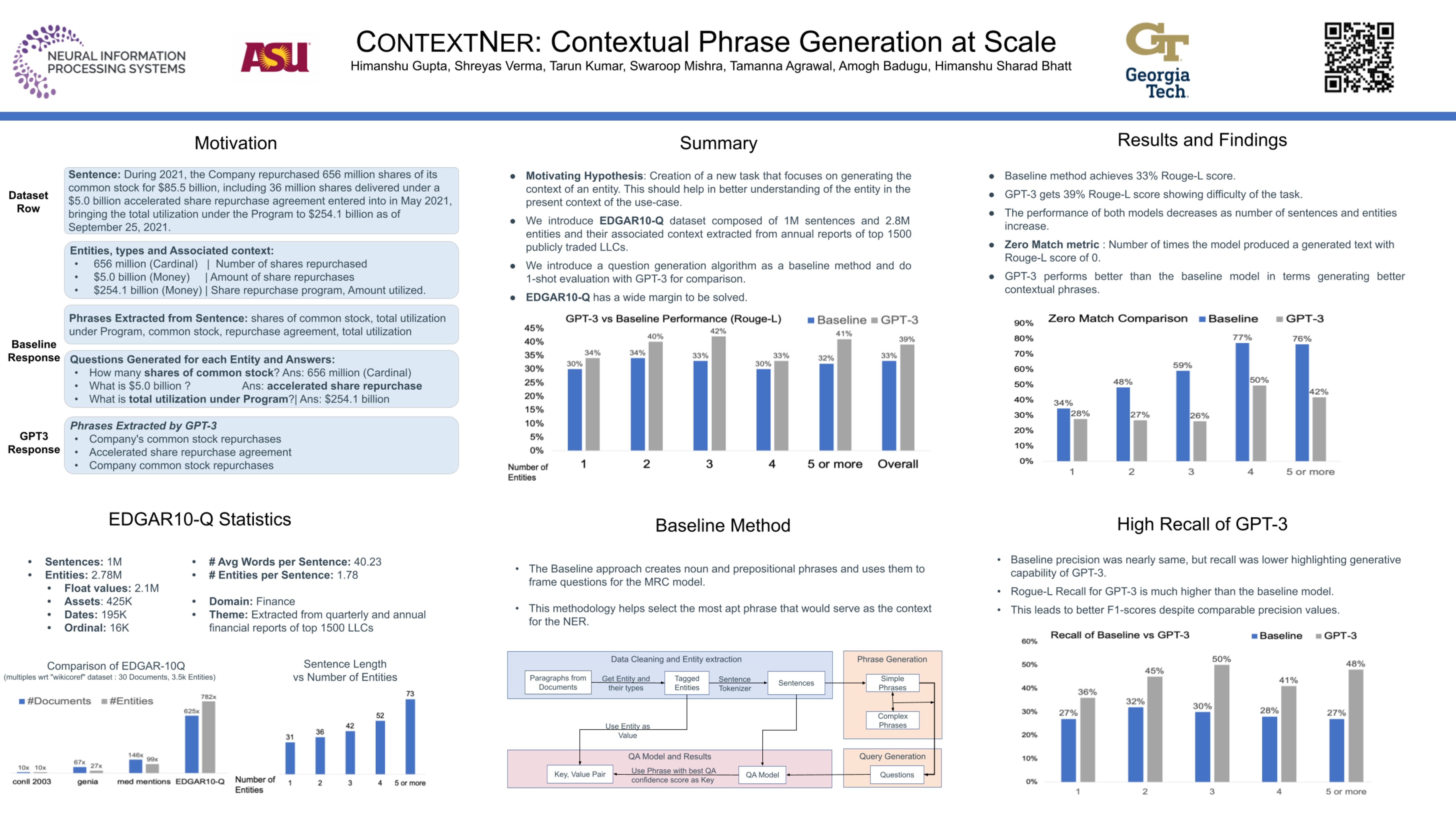
NLP research has been focused on NER extraction and how to efficiently extract them from a sentence. However, generating relevant context of entities from a sentence has remained under-explored. In this work, we introduce the task Context-NER in which relevant context of an entity has to be generated. The extracted context may not be found exactly as a substring in the sentence. We also introduce the EDGAR10-Q dataset for the same, which is a corpus of 1,500 publicly traded companies. It is a manually created complex corpus and one of the largest in terms of number of sentences and entities (1 M and 2.8 M). We introduce a baseline approach that leverages phrase generation algorithms and uses the pre-trained BERT model to get 33% ROUGE-L score. We also do a one shot evaluation with GPT-3 and get 39% score, signifying the hardness and future scope of this task. We hope that addition of this dataset and our study will pave the way for further research in this domain.