Pre-Training a Graph Recurrent Network for Language Representation
{kind=link}
Abstract
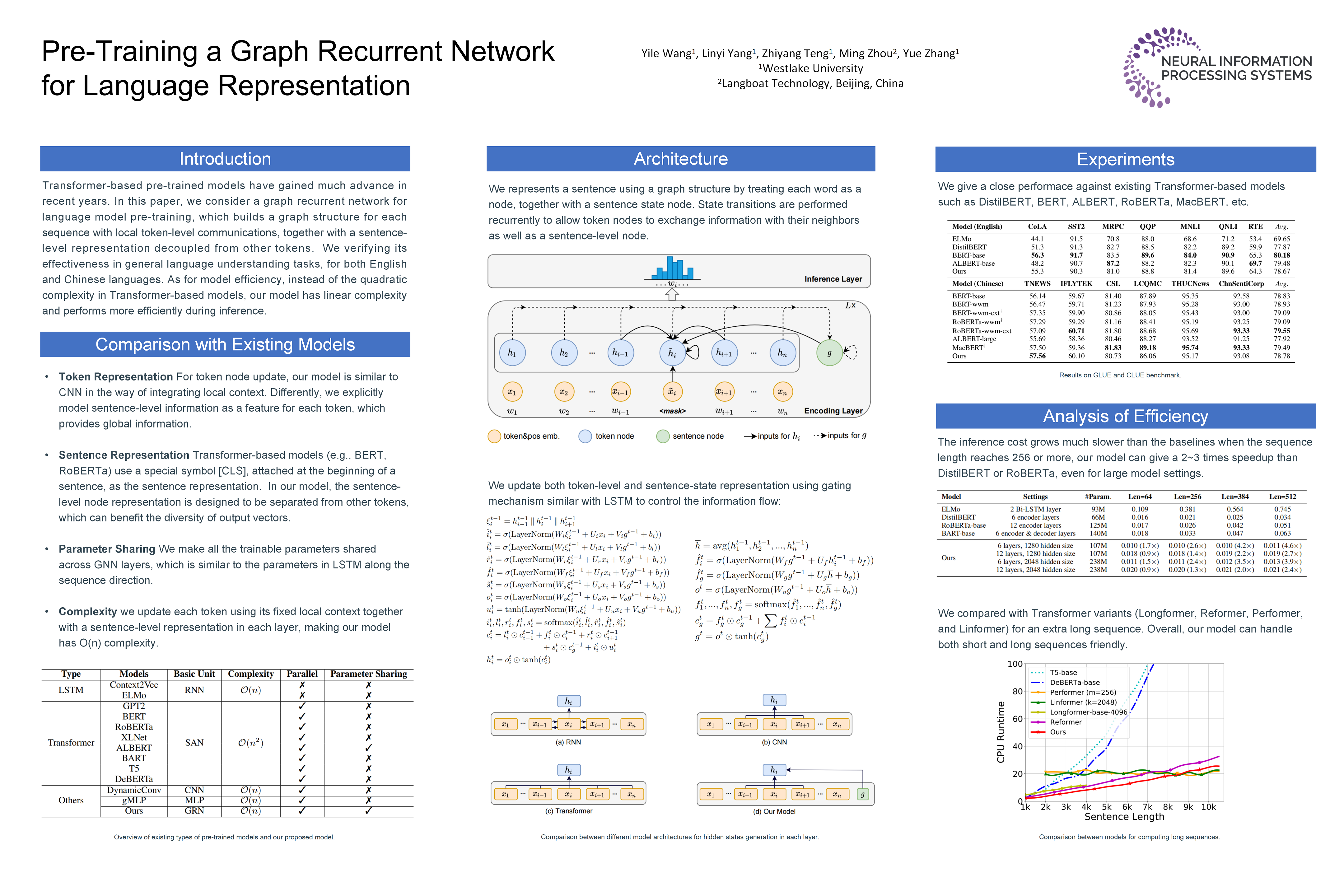
Transformer-based models have gained much advance in recent years, becoming one of the most important backbones in natural language processing. Recent work shows that the attention mechanism in Transformer may not be necessary, both convolutional neural networks and multi-layer perceptron based models have been investigated as Transformer alternatives. In this paper, we consider a graph recurrent network for language model pre-training, which builds a graph structure for each sequence with local token-level communications, together with a sentence-level representation decoupled from other tokens. We find such architecture can give comparable results against Transformer-based ones in both English and Chinese language benchmarks. Moreover, instead of the quadratic complexity, our model has linear complexity and performs more efficiently during inference. Our models and code will be released for further research.