Fast-in-Slow: A Dual-System VLA Model Unifying Fast Manipulation within Slow Reasoning
{kind=link}
Abstract
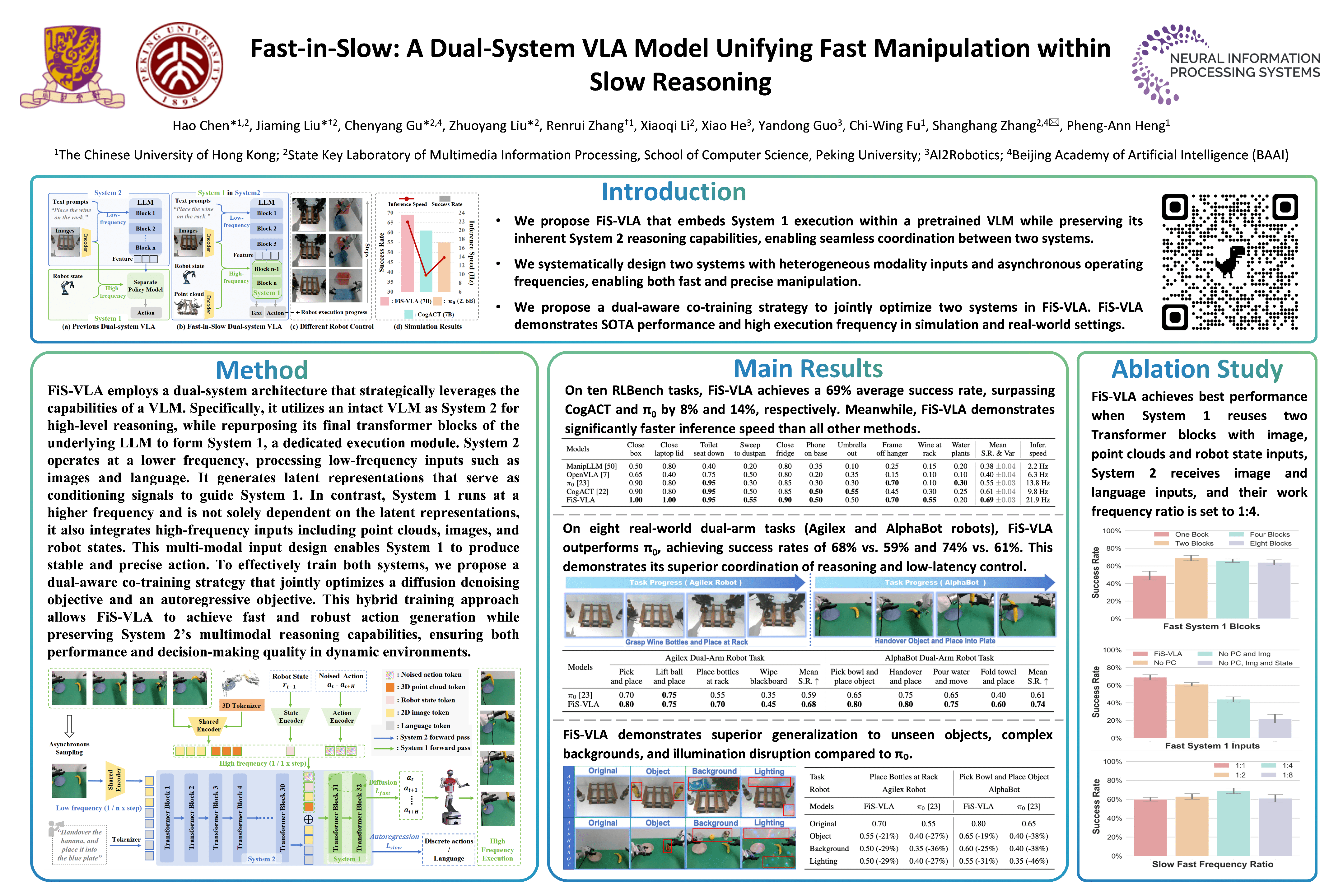
Generalized policy and execution efficiency constitute the two critical challenges in robotic manipulation. While recent foundation policies benefit from the common-sense reasoning capabilities of internet-scale pretrained vision-language models (VLMs), they often suffer from low execution frequency. To mitigate this dilemma, dual-system approaches have been proposed to leverage a VLM-based System 2 module for handling high-level decision-making, and a separate System 1 action module for ensuring real-time control. However, existing designs maintain both systems as separate models, limiting System 1 from fully leveraging the rich pretrained knowledge from the VLM-based System 2. In this work, we propose Fast-in-Slow (FiS), a unified dual-system vision-language-action (VLA) model that embeds the System 1 execution module within the VLM-based System 2 by partially sharing parameters. This innovative paradigm not only enables high-frequency execution in System 1, but also facilitates coordination between multimodal reasoning and execution components within a single foundation model of System 2. Given their fundamentally distinct roles within FiS-VLA, we design the two systems to incorporate heterogeneous modality inputs alongside asynchronous operating frequencies, enabling both fast and precise manipulation. To enable coordination between the two systems, a dual-aware co-training strategy is proposed that equips System 1 with action generation capabilities while preserving System 2’s contextual understanding to provide stable latent conditions for System 1. For evaluation, FiS-VLA outperforms previous state-of-the-art methods by 8% in simulation and 11% in real-world tasks in terms of average success rate, while achieving a 117.7 Hz control frequency with action chunk set to eight. Project web page: https://fast-in-slow.github.io.