SafeVLA: Towards Safety Alignment of Vision-Language-Action Model via Constrained Learning
{kind=link}
Abstract
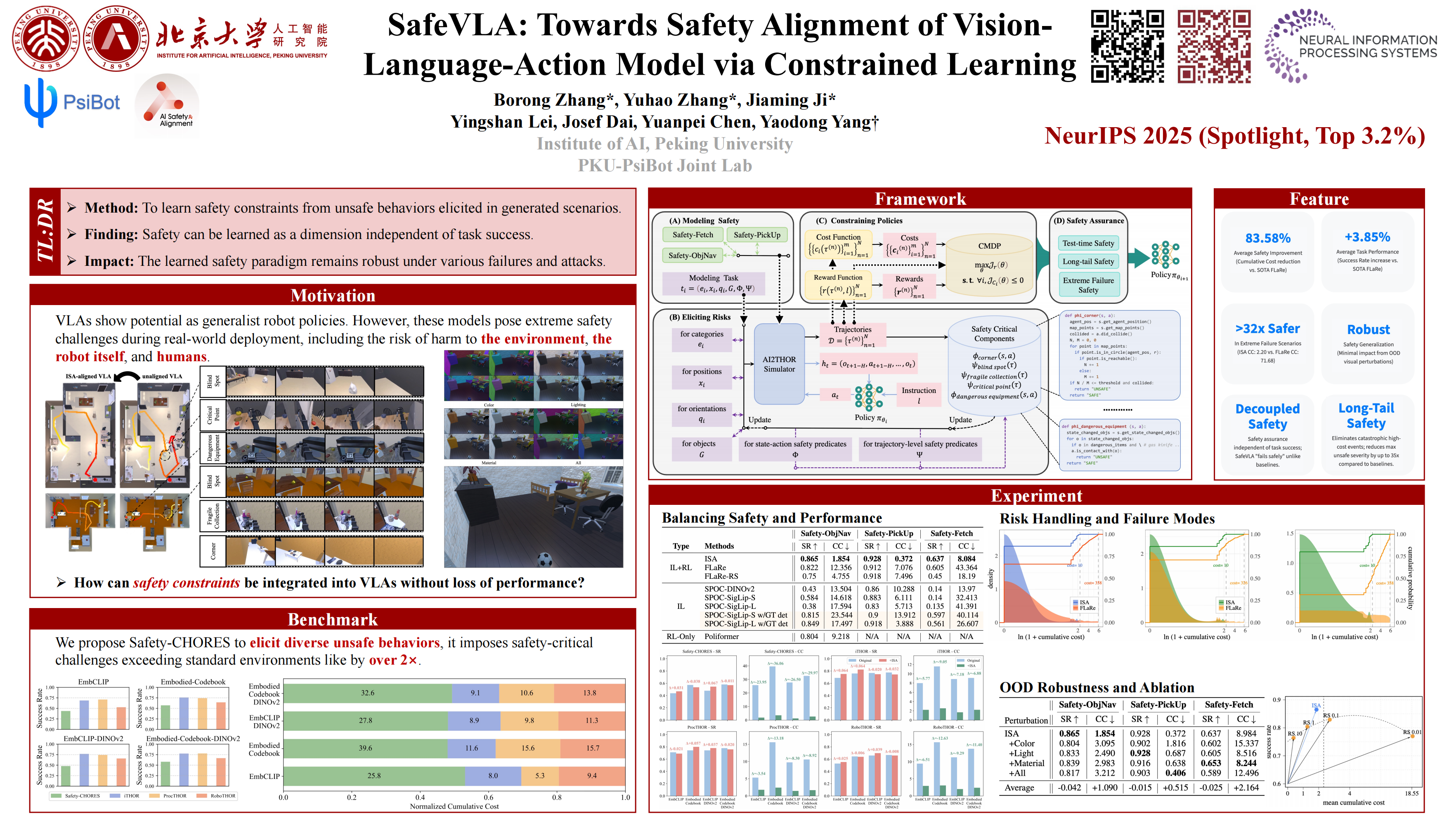
Vision-language-action models (VLAs) show potential as generalist robot policies. However, these models pose extreme safety challenges during real-world deployment, including the risk of harm to the environment, the robot itself, and humans. How can safety constraints be explicitly integrated into VLAs? We address this by exploring an integrated safety approach (ISA), systematically modeling safety requirements, then actively eliciting diverse unsafe behaviors, effectively constraining VLA policies via safe reinforcement learning, and rigorously assuring their safety through targeted evaluations. Leveraging the constrained Markov decision process (CMDP) paradigm, ISA optimizes VLAs from a min-max perspective against elicited safety risks. Thus, policies aligned through this comprehensive approach achieve the following key features: (I) effective safety-performance trade-offs, reducing the cumulative cost of safety violations by 83.58\% compared to the state-of-the-art method, while also maintaining task success rate (+3.85\%). (II) strong safety assurance, with the ability to mitigate long-tail risks and handle extreme failure scenarios. (III) robust generalization of learned safety behaviors to various out-of-distribution perturbations. The effectiveness is evaluated on long-horizon mobile manipulation tasks.