BridgeVLA: Input-Output Alignment for Efficient 3D Manipulation Learning with Vision-Language Models
Peiyan Li ⋅ Yixiang Chen ⋅ Hongtao Wu ⋅ Xiao Ma ⋅ Xiangnan Wu ⋅ Yan Huang ⋅ Liang Wang ⋅ Tao Kong ⋅ Tieniu Tan
2025 Poster
{kind=link}
Abstract
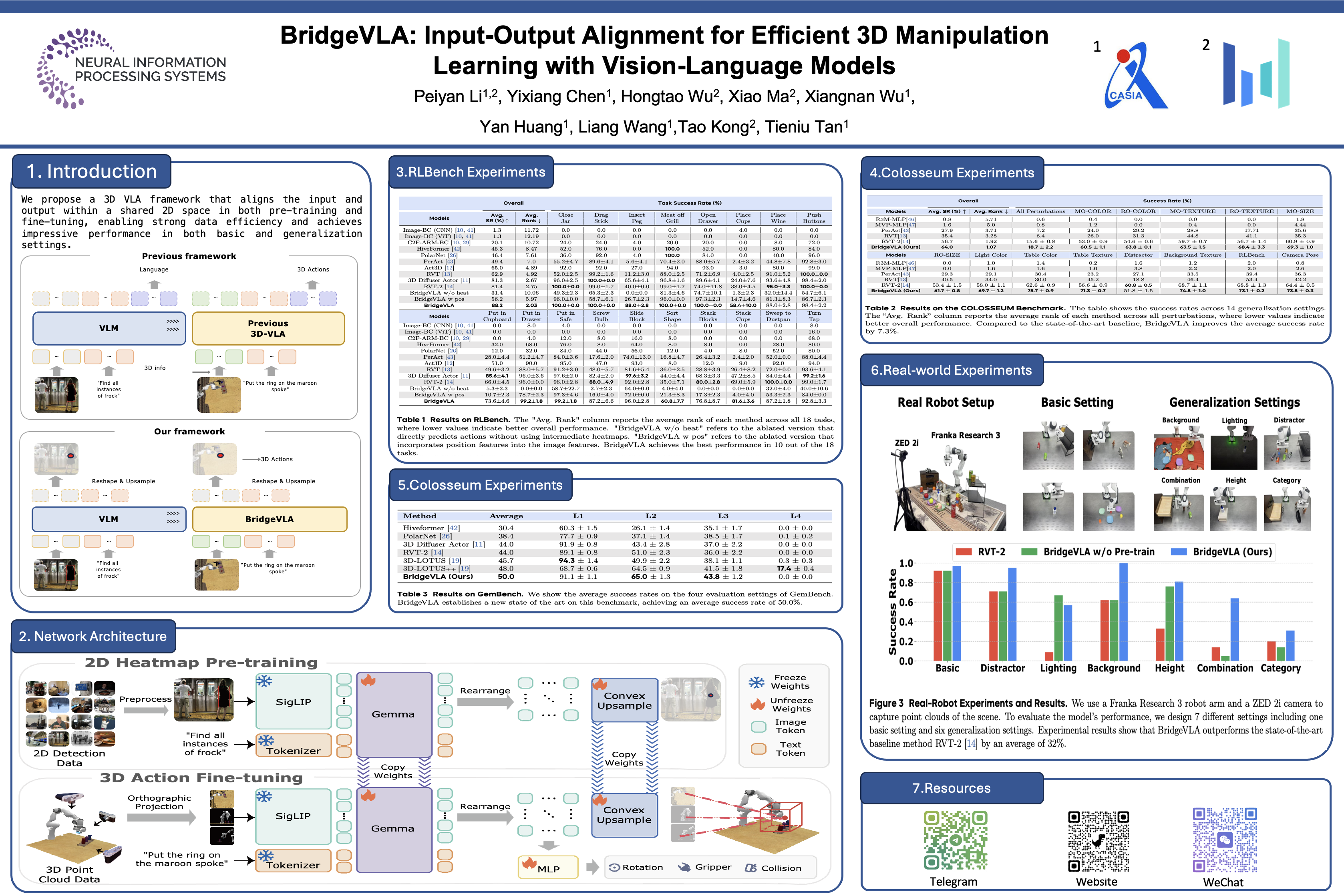
Recently, leveraging pre-trained vision-language models (VLMs) for building vision-language-action (VLA) models has emerged as a promising approach to effective robot manipulation learning. However, only few methods incorporate 3D signals into VLMs for action prediction, and they do not fully leverage the spatial structure inherent in 3D data, leading to low data efficiency. In this paper, we introduce a new paradigm for constructing 3D VLAs. Specifically, we first pre-train the VLM backbone to take 2D images as input and produce 2D heatmaps as output. Using this pre-trained VLM as the backbone, we then fine-tune the entire VLA model while maintaining alignment between inputs and outputs by: (1) projecting raw point cloud inputs into multi-view images, and (2) predicting heatmaps before generating the final action. Extensive experiments show that the resulting model, BridgeVLA, can learn 3D manipulation both efficiently and effectively. BridgeVLA outperforms state-of-the-art baselines across three simulation benchmarks. In RLBench, it improves the average success rate from 81.4\% to 88.2\%. In COLOSSEUM, it demonstrates significantly better performance in challenging generalization settings, boosting the average success rate from 56.7\% to 64.0\%. In GemBench, it surpasses all the comparing baseline methods in terms of average success rate. In real-robot experiments, BridgeVLA outperforms a state-of-the-art baseline method by 32\% on average. It generalizes robustly in multiple out-of-distribution settings, including visual disturbances and unseen instructions. Remarkably, it is able to achieve a success rate of 95.4\% on 10+ tasks with only 3 trajectories per task, while other VLA methods such as $\pi_{0}$ fail completely. Project Website: https://bridgevla.github.io/.
Video
Chat is not available.
Successful Page Load