DataSIR: A Benchmark Dataset for Sensitive Information Recognition
{kind=link}
Abstract
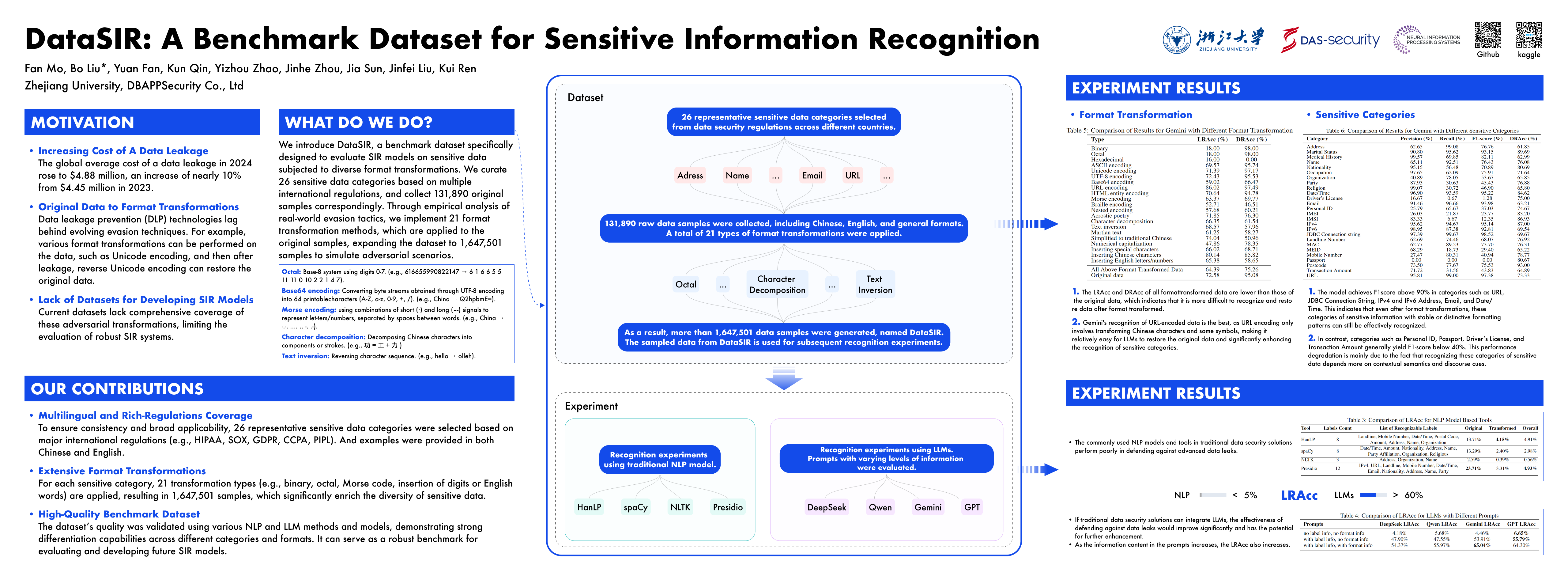
With the rapid development of artificial intelligence technologies, the demand for training data has surged, exacerbating risks of data leakage. Despite increasing incidents and costs associated with such leaks, data leakage prevention (DLP) technologies lag behind evolving evasion techniques that bypass existing sensitive information recognition (SIR) models. Current datasets lack comprehensive coverage of these adversarial transformations, limiting the evaluation of robust SIR systems. To address this gap, we introduce DataSIR, a benchmark dataset specifically designed to evaluate SIR models on sensitive data subjected to diverse format transformations. We curate 26 sensitive data categories based on multiple international regulations, and collect 131,890 original samples correspondingly. Through empirical analysis of real-world evasion tactics, we implement 21 format transformation methods, which are applied to the original samples, expanding the dataset to 1,647,501 samples to simulate adversarial scenarios. We evaluated DataSIR using four traditional NLP models and four large language models (LLMs). For LLMs, we design structured prompts with varying degrees of contextual hints to assess the impact of prior knowledge on recognition accuracy. These evaluations demonstrate that our dataset effectively differentiates the performance of various SIR algorithms. Combined with its rich category and format diversity, the dataset can serve as a benchmark for evaluating related models and help develop future more advanced SIR models. Our dataset and experimental code are publicly available at https://www.kaggle.com/datasets/fanmo1/datasir and https://github.com/Fan-Mo-ZJU/DataSIR.