Benchmarking Robustness to Adversarial Image Obfuscations
{kind=link}
Abstract
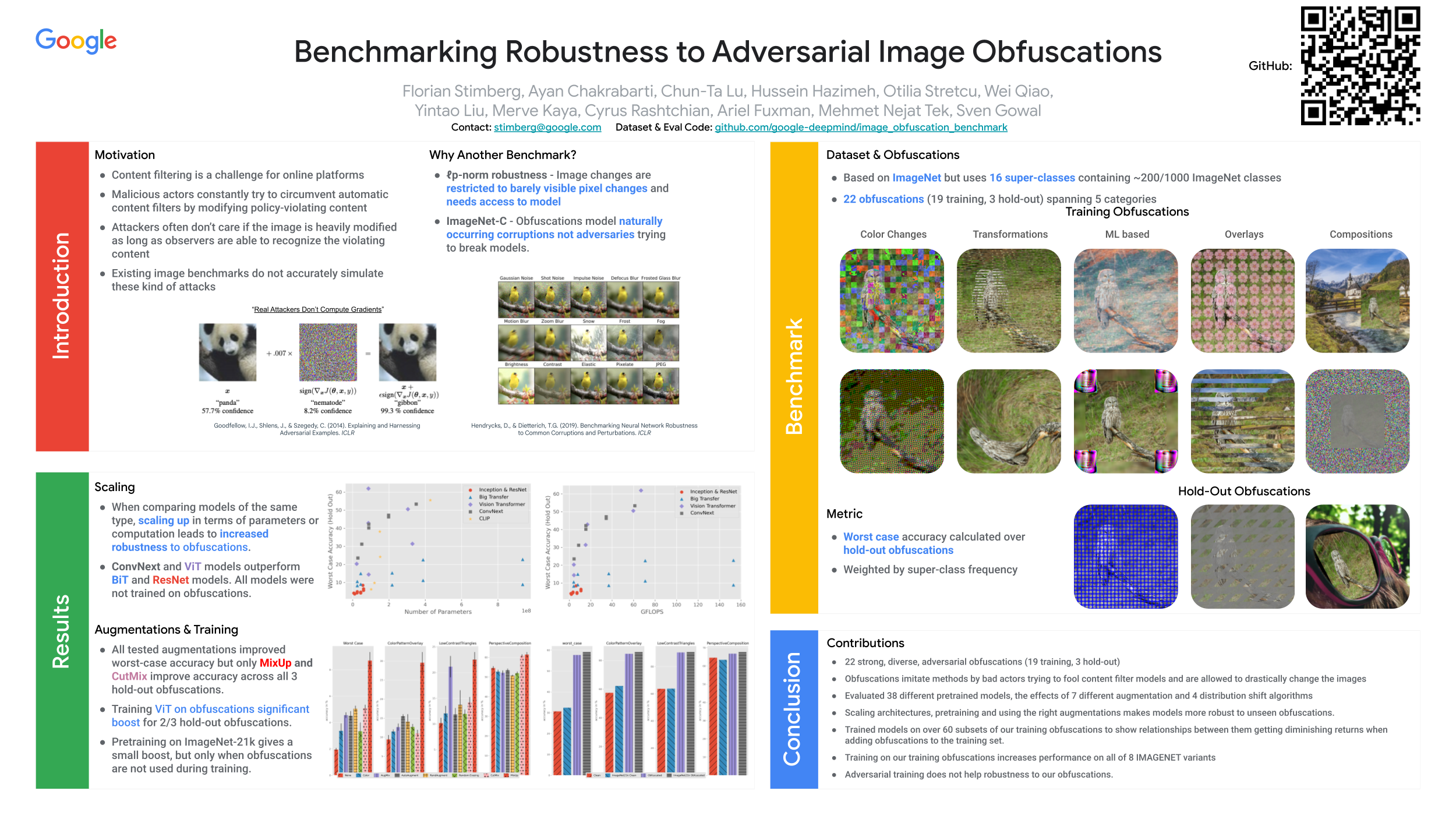
Automated content filtering and moderation is an important tool that allows online platforms to build striving user communities that facilitate cooperation and prevent abuse. Unfortunately, resourceful actors try to bypass automated filters in a bid to post content that violate platform policies and codes of conduct. To reach this goal, these malicious actors may obfuscate policy violating images (e.g., overlay harmful images by carefully selected benign images or visual patterns) to prevent machine learning models from reaching the correct decision. In this paper, we invite researchers to tackle this specific issue and present a new image benchmark. This benchmark, based on ImageNet, simulates the type of obfuscations created by malicious actors. It goes beyond Image-Net-C and ImageNet-C-bar by proposing general, drastic, adversarial modifications that preserve the original content intent. It aims to tackle a more common adversarial threat than the one considered by lp-norm bounded adversaries. We evaluate 33 pretrained models on the benchmark and train models with different augmentations, architectures and training methods on subsets of the obfuscations to measure generalization. Our hope is that this benchmark will encourage researchers to test their models and methods and try to find new approaches that are more robust to these obfuscations.