Towards Federated Foundation Models: Scalable Dataset Pipelines for Group-Structured Learning
{kind=link}
Abstract
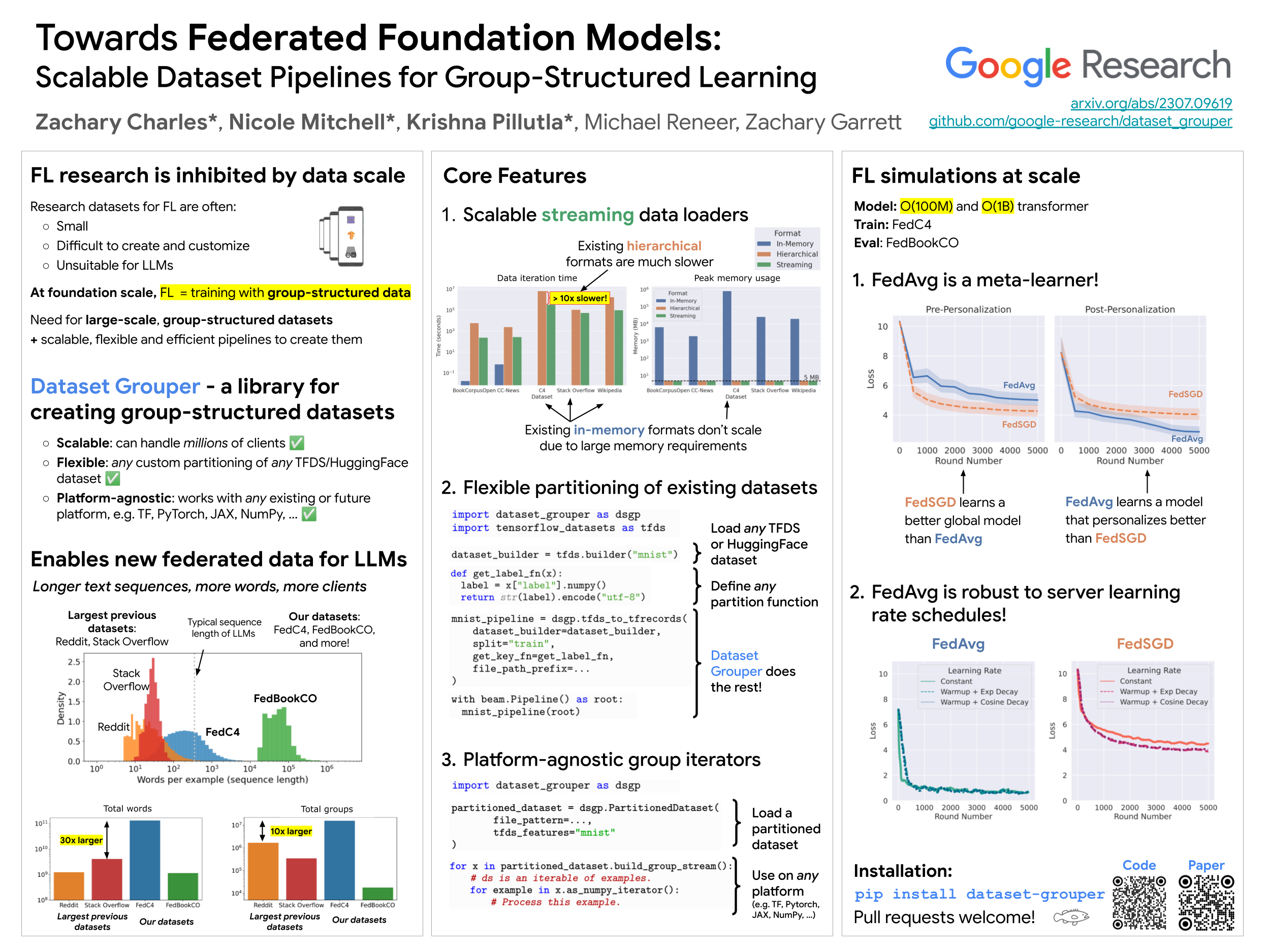
We introduce Dataset Grouper, a library to create large-scale group-structured (e.g., federated) datasets, enabling federated learning simulation at the scale of foundation models. This library facilitates the creation of group-structured versions of existing datasets based on user-specified partitions, and directly leads to a variety of useful heterogeneous datasets that can be plugged into existing software frameworks. Dataset Grouper offers three key advantages. First, it scales to settings where even a single group's dataset is too large to fit in memory. Second, it provides flexibility, both in choosing the base (non-partitioned) dataset and in defining partitions. Finally, it is framework-agnostic. We empirically demonstrate that Dataset Grouper enables large-scale federated language modeling simulations on datasets that are orders of magnitude larger than in previous work, allowing for federated training of language models with hundreds of millions, and even billions, of parameters. Our experimental results show that algorithms like FedAvg operate more as meta-learning methods than as empirical risk minimization methods at this scale, suggesting their utility in downstream personalization and task-specific adaptation. Dataset Grouper is available at https://github.com/google-research/dataset_grouper.