M3Exam: A Multilingual, Multimodal, Multilevel Benchmark for Examining Large Language Models
{kind=link}
Abstract
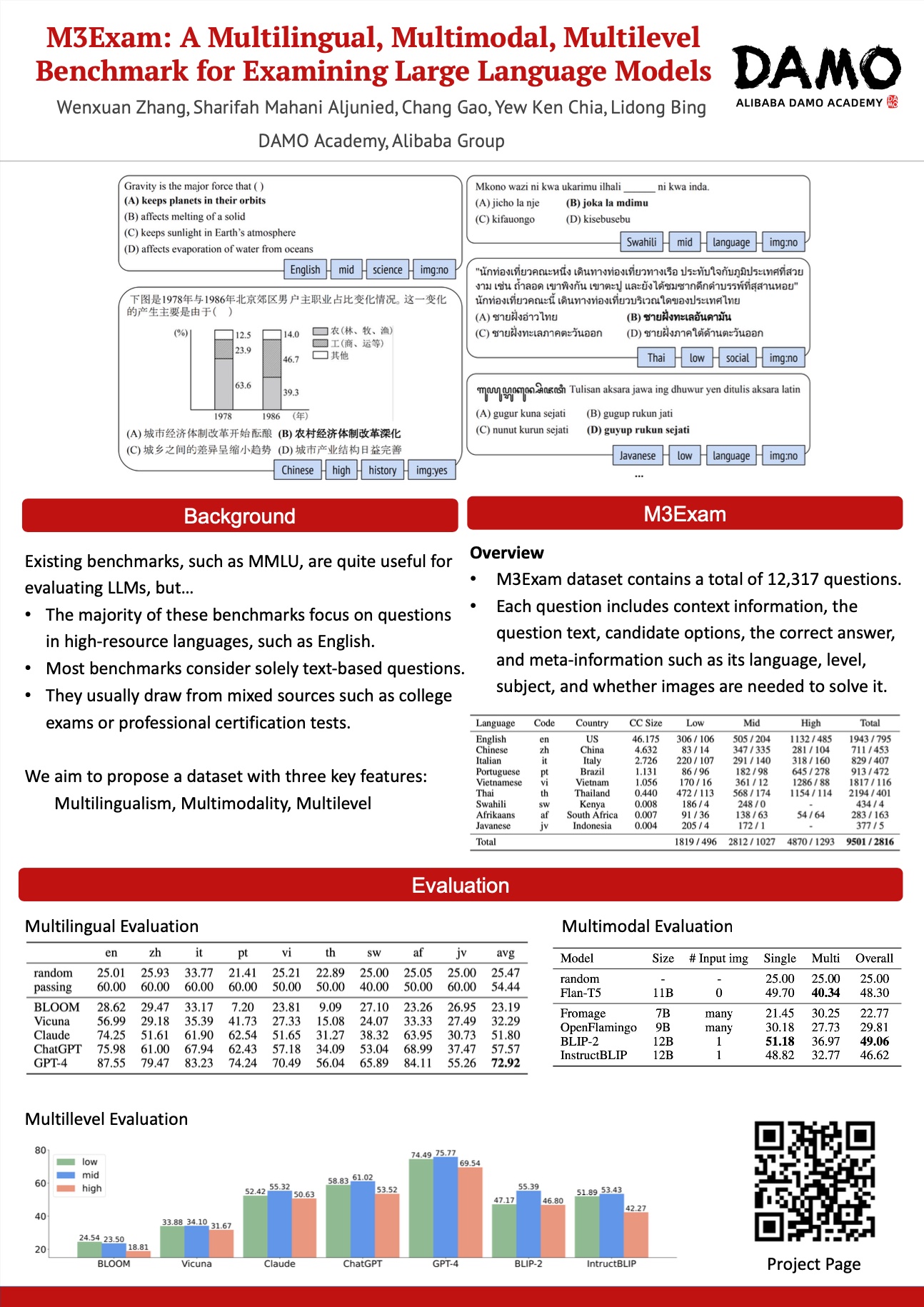
Despite the existence of various benchmarks for evaluating natural language processing models, we argue that human exams are a more suitable means of evaluating general intelligence for large language models (LLMs), as they inherently demand a much wider range of abilities such as language understanding, domain knowledge, and problem-solving skills. To this end, we introduce M3Exam, a novel benchmark sourced from real and official human exam questions for evaluating LLMs in a multilingual, multimodal, and multilevel context. M3Exam exhibits three unique characteristics: (1) multilingualism, encompassing questions from multiple countries that require strong multilingual proficiency and cultural knowledge; (2) multimodality, accounting for the multimodal nature of many exam questions to test the model's multimodal understanding capability; and (3) multilevel structure, featuring exams from three critical educational periods to comprehensively assess a model's proficiency at different levels. In total, M3Exam contains 12,317 questions in 9 diverse languages with three educational levels, where about 23\% of the questions require processing images for successful solving. We assess the performance of top-performing LLMs on M3Exam and find that current models, including GPT-4, still struggle with multilingual text, particularly in low-resource and non-Latin script languages. Multimodal LLMs also perform poorly with complex multimodal questions. We believe that M3Exam can be a valuable resource for comprehensively evaluating LLMs by examining their multilingual and multimodal abilities and tracking their development. Data and evaluation code is available at \url{https://github.com/DAMO-NLP-SG/M3Exam}.