Two Heads are Better Than One: A Simple Exploration Framework for Efficient Multi-Agent Reinforcement Learning
{kind=link}
Abstract
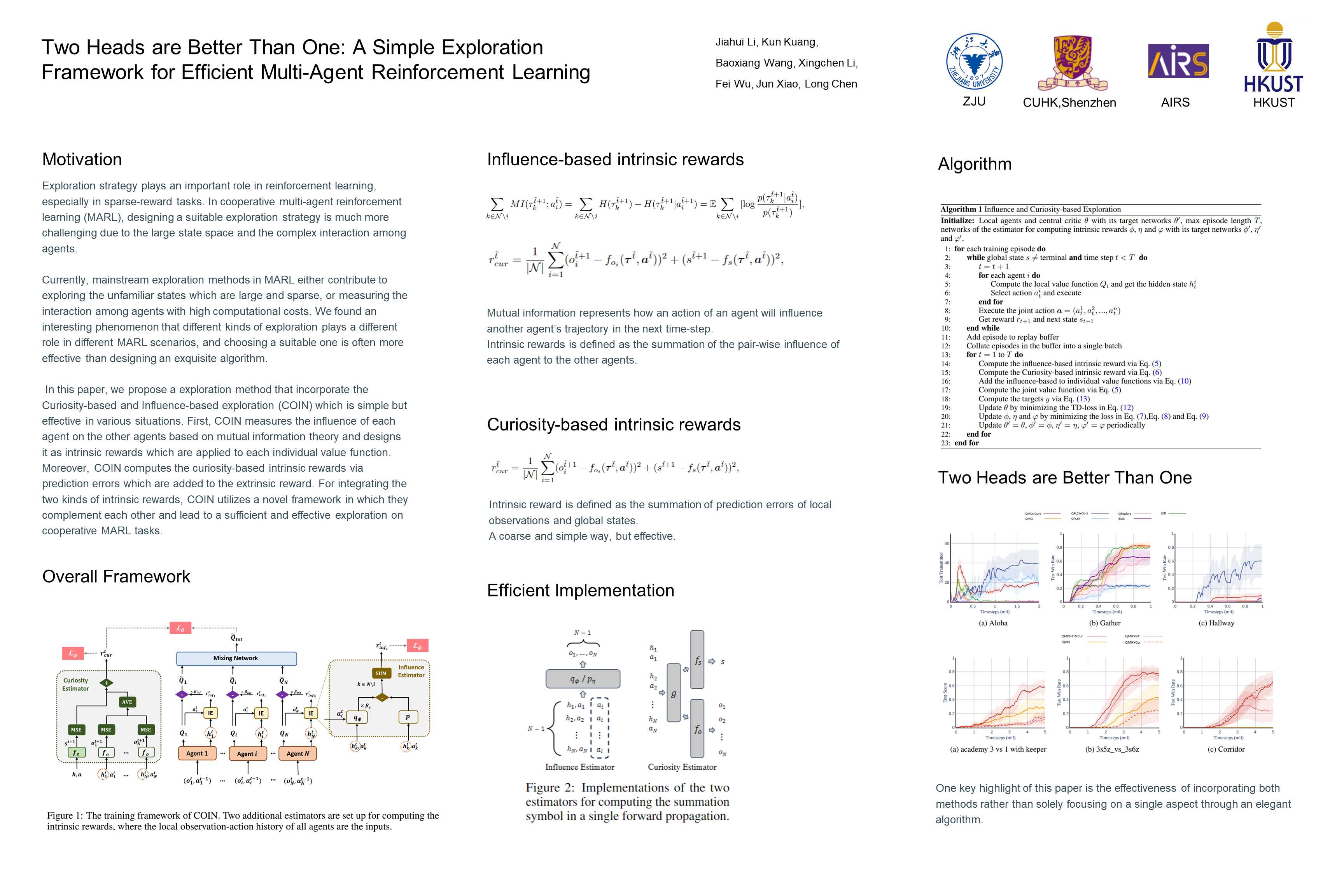
Exploration strategy plays an important role in reinforcement learning, especially in sparse-reward tasks. In cooperative multi-agent reinforcement learning~(MARL), designing a suitable exploration strategy is much more challenging due to the large state space and the complex interaction among agents. Currently, mainstream exploration methods in MARL either contribute to exploring the unfamiliar states which are large and sparse, or measuring the interaction among agents with high computational costs. We found an interesting phenomenon that different kinds of exploration plays a different role in different MARL scenarios, and choosing a suitable one is often more effective than designing an exquisite algorithm. In this paper, we propose a exploration method that incorporate the \underline{C}uri\underline{O}sity-based and \underline{IN}fluence-based exploration~(COIN) which is simple but effective in various situations. First, COIN measures the influence of each agent on the other agents based on mutual information theory and designs it as intrinsic rewards which are applied to each individual value function. Moreover, COIN computes the curiosity-based intrinsic rewards via prediction errors which are added to the extrinsic reward. For integrating the two kinds of intrinsic rewards, COIN utilizes a novel framework in which they complement each other and lead to a sufficient and effective exploration on cooperative MARL tasks. We perform extensive experiments on different challenging benchmarks, and results across different scenarios show the superiority of our method.