Kronecker-Factored Approximate Curvature for Modern Neural Network Architectures
Runa Eschenhagen ⋅ Alexander Immer ⋅ Richard Turner ⋅ Frank Schneider ⋅ Philipp Hennig
2023 Spotlight Poster
{kind=link}
Abstract
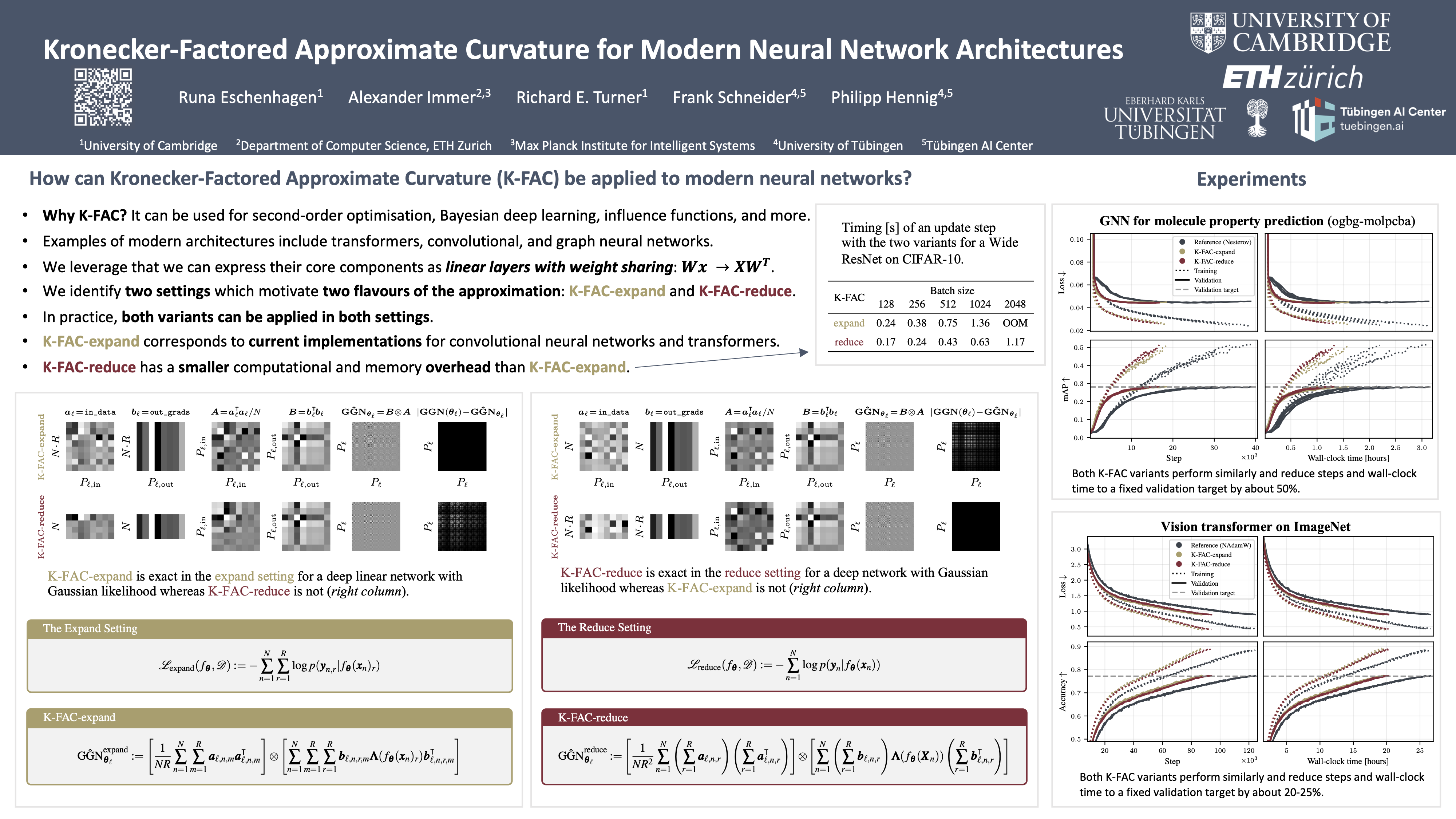
The core components of many modern neural network architectures, such as transformers, convolutional, or graph neural networks, can be expressed as linear layers with *weight-sharing*. Kronecker-Factored Approximate Curvature (K-FAC), a second-order optimisation method, has shown promise to speed up neural network training and thereby reduce computational costs. However, there is currently no framework to apply it to generic architectures, specifically ones with linear weight-sharing layers. In this work, we identify two different settings of linear weight-sharing layers which motivate two flavours of K-FAC -- *expand* and *reduce*. We show that they are exact for deep linear networks with weight-sharing in their respective setting. Notably, K-FAC-reduce is generally faster than K-FAC-expand, which we leverage to speed up automatic hyperparameter selection via optimising the marginal likelihood for a Wide ResNet. Finally, we observe little difference between these two K-FAC variations when using them to train both a graph neural network and a vision transformer. However, both variations are able to reach a fixed validation metric target in $50$-$75$\% of the number of steps of a first-order reference run, which translates into a comparable improvement in wall-clock time. This highlights the potential of applying K-FAC to modern neural network architectures.
Video
Chat is not available.
Successful Page Load