Feature Dropout: Revisiting the Role of Augmentations in Contrastive Learning
{kind=link}
Abstract
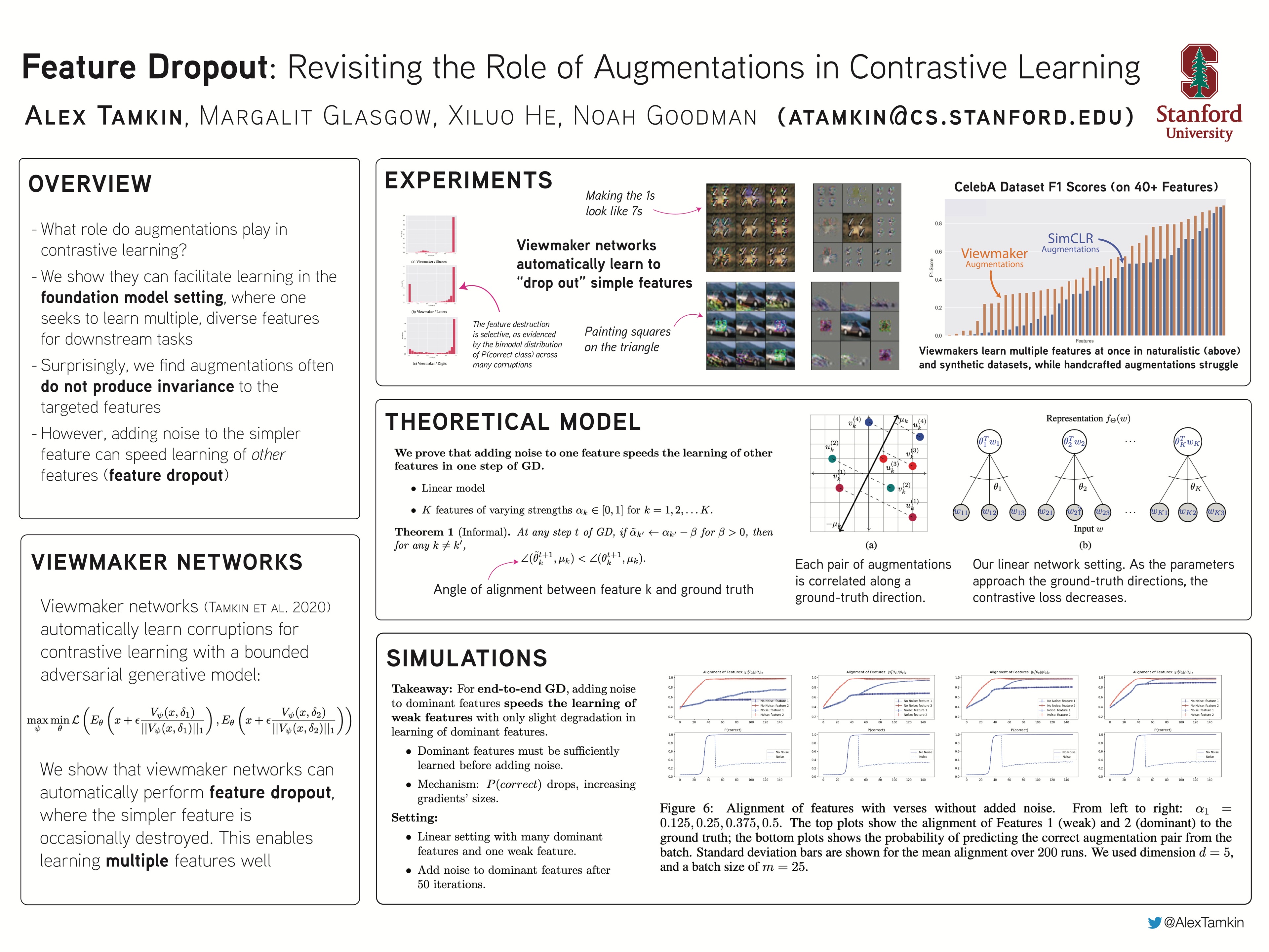
What role do augmentations play in contrastive learning? Recent work suggests that good augmentations are label-preserving with respect to a specific downstream task. We complicate this picture by showing that label-destroying augmentations can be useful in the foundation model setting, where the goal is to learn diverse, general-purpose representations for multiple downstream tasks. We perform contrastive learning experiments on a range of image and audio datasets with multiple downstream tasks (e.g. for digits superimposed on photographs, predicting the class of one vs. the other). We find that Viewmaker Networks, a recently proposed model for learning augmentations for contrastive learning, produce label-destroying augmentations that stochastically destroy features needed for different downstream tasks. These augmentations are interpretable (e.g. altering shapes, digits, or letters added to images) and surprisingly often result in better performance compared to expert-designed augmentations, despite not preserving label information. To support our empirical results, we theoretically analyze a simple contrastive learning setting with a linear model. In this setting, label-destroying augmentations are crucial for preventing one set of features from suppressing the learning of features useful for another downstream task. Our results highlight the need for analyzing the interaction between multiple downstream tasks when trying to explain the success of foundation models.