Should Under-parameterized Student Networks Copy or Average Teacher Weights?
Berfin Simsek ⋅ Amire Bendjeddou ⋅ Wulfram Gerstner ⋅ Johanni Brea
2023 Poster
{kind=link}
Abstract
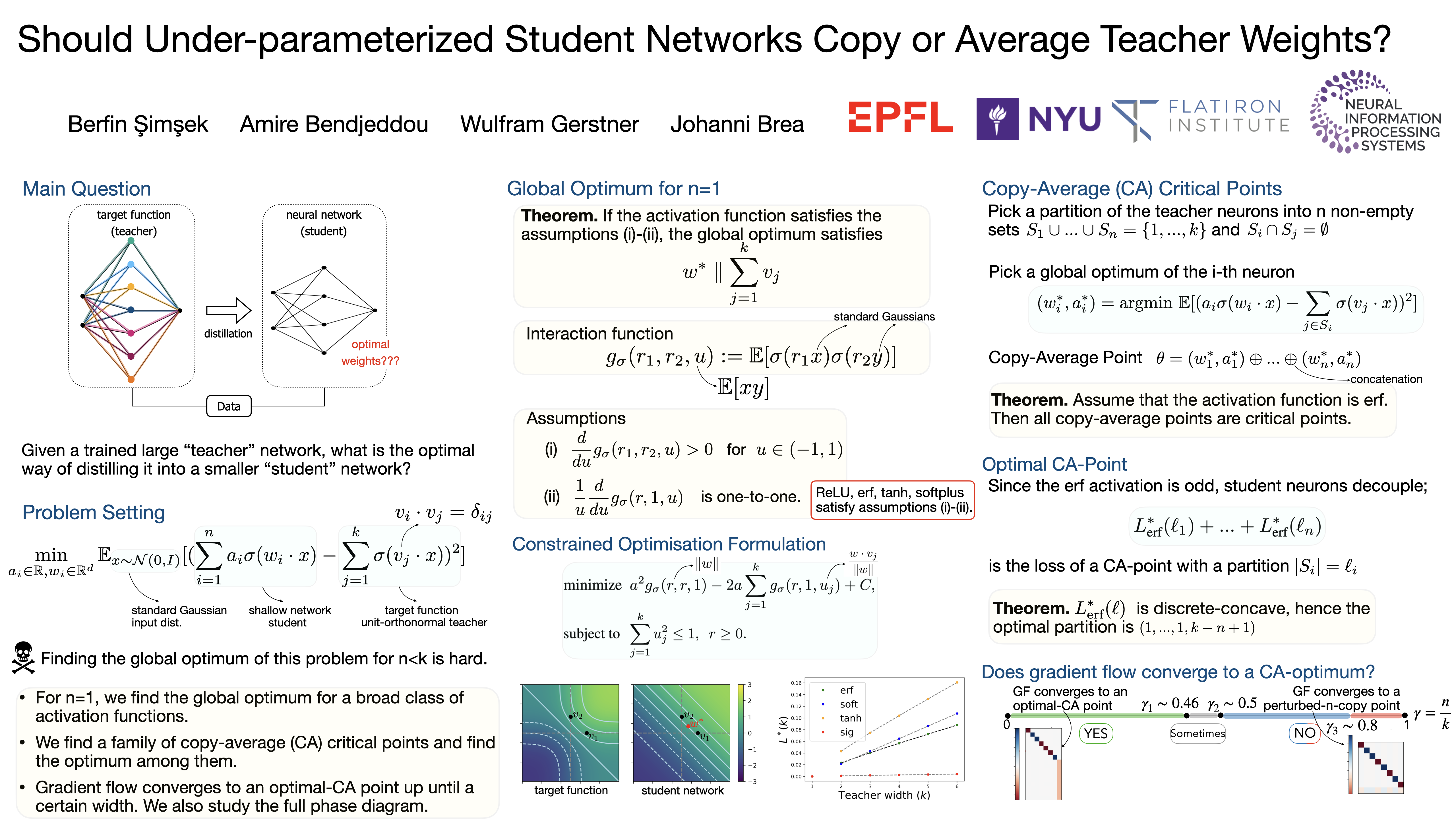
Any continuous function $f^*$ can be approximated arbitrarily well by a neural network with sufficiently many neurons $k$. We consider the case when $f^*$ itself is a neural network with one hidden layer and $k$ neurons. Approximating $f^*$ with a neural network with $n< k$ neurons can thus be seen as fitting an under-parameterized "student" network with $n$ neurons to a "teacher" network with $k$ neurons. As the student has fewer neurons than the teacher, it is unclear, whether each of the $n$ student neurons should copy one of the teacher neurons or rather average a group of teacher neurons. For shallow neural networks with erf activation function and for the standard Gaussian input distribution, we prove that "copy-average" configurations are critical points if the teacher's incoming vectors are orthonormal and its outgoing weights are unitary. Moreover, the optimum among such configurations is reached when $n-1$ student neurons each copy one teacher neuron and the $n$-th student neuron averages the remaining $k-n+1$ teacher neurons. For the student network with $n=1$ neuron, we provide additionally a closed-form solution of the non-trivial critical point(s) for commonly used activation functions through solving an equivalent constrained optimization problem. Empirically, we find for the erf activation function that gradient flow converges either to the optimal copy-average critical point or to another point where each student neuron approximately copies a different teacher neuron. Finally, we find similar results for the ReLU activation function, suggesting that the optimal solution of underparameterized networks has a universal structure.
Video
Chat is not available.
Successful Page Load