Adversarial Robustness through Random Weight Sampling
{kind=link}
Abstract
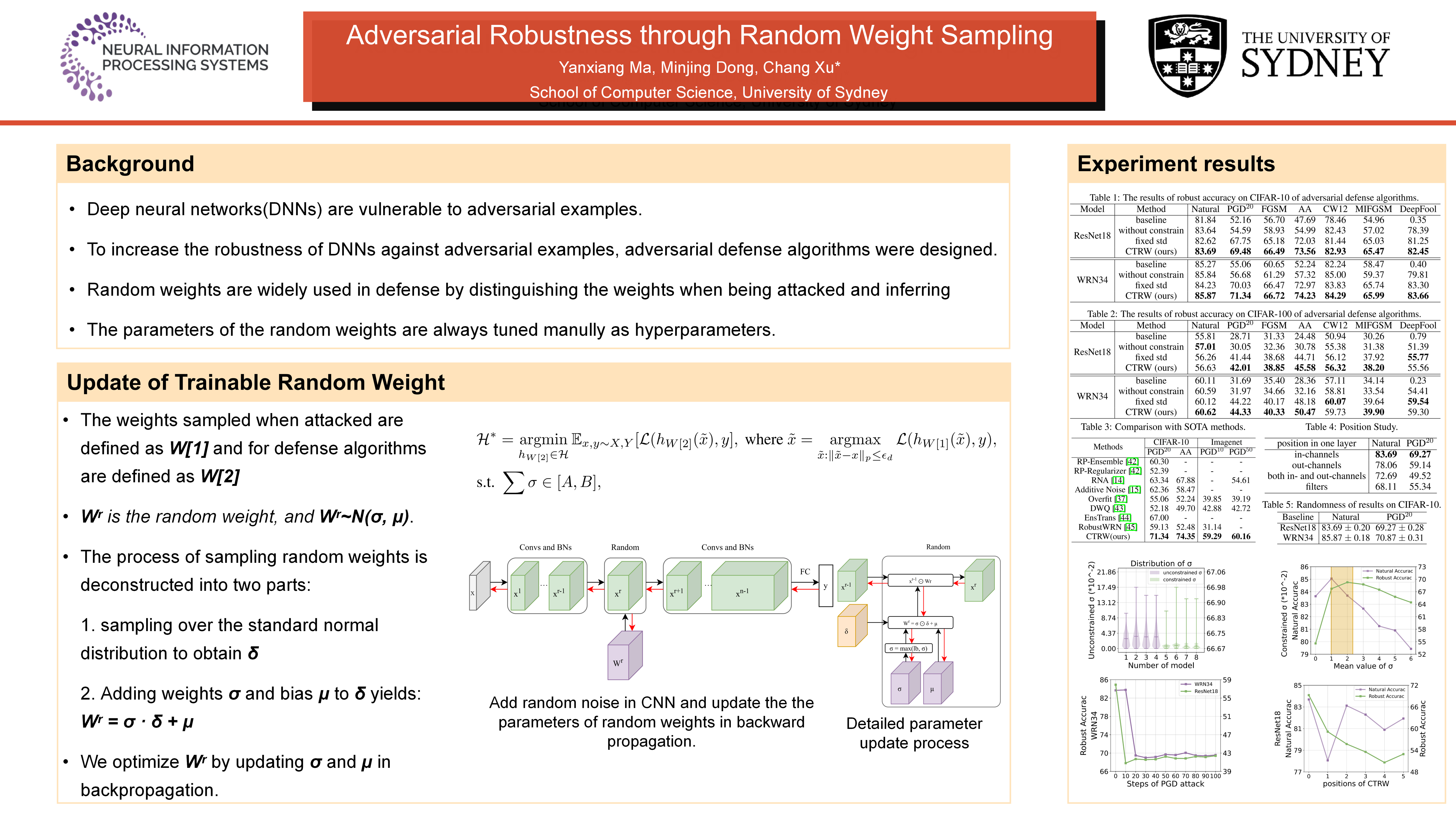
Deep neural networks have been found to be vulnerable in a variety of tasks. Adversarial attacks can manipulate network outputs, resulting in incorrect predictions. Adversarial defense methods aim to improve the adversarial robustness of networks by countering potential attacks. In addition to traditional defense approaches, randomized defense mechanisms have recently received increasing attention from researchers. These methods introduce different types of perturbations during the inference phase to destabilize adversarial attacks.Although promising empirical results have been demonstrated by these approaches, the defense performance is quite sensitive to the randomness parameters, which are always manually tuned without further analysis. On the contrary, we propose incorporating random weights into the optimization to fully exploit the potential of randomized defense. To perform better optimization of randomness parameters, we conduct a theoretical analysis of the connections between randomness parameters and gradient similarity as well as natural performance. From these two aspects, we suggest imposing theoretically-guided constraints on random weights during optimizations, as these weights play a critical role in balancing natural performance and adversarial robustness. We derive both the upper and lower bounds of random weight parameters by considering prediction bias and gradient similarity. In this study, we introduce the Constrained Trainable Random Weight (CTRW), which adds random weight parameters to the optimization and includes a constraint guided by the upper and lower bounds to achieve better trade-offs between natural and robust accuracy. We evaluate the effectiveness of CTRW on several datasets and benchmark convolutional neural networks. Our results indicate that our model achieves a robust accuracy approximately 16% to 17% higher than the baseline model under PGD-20 and 22% to 25% higher on Auto Attack.