Guarantees for Self-Play in Multiplayer Games via Polymatrix Decomposability
Revan MacQueen ⋅ James Wright
2023 Poster
{kind=link}
Abstract
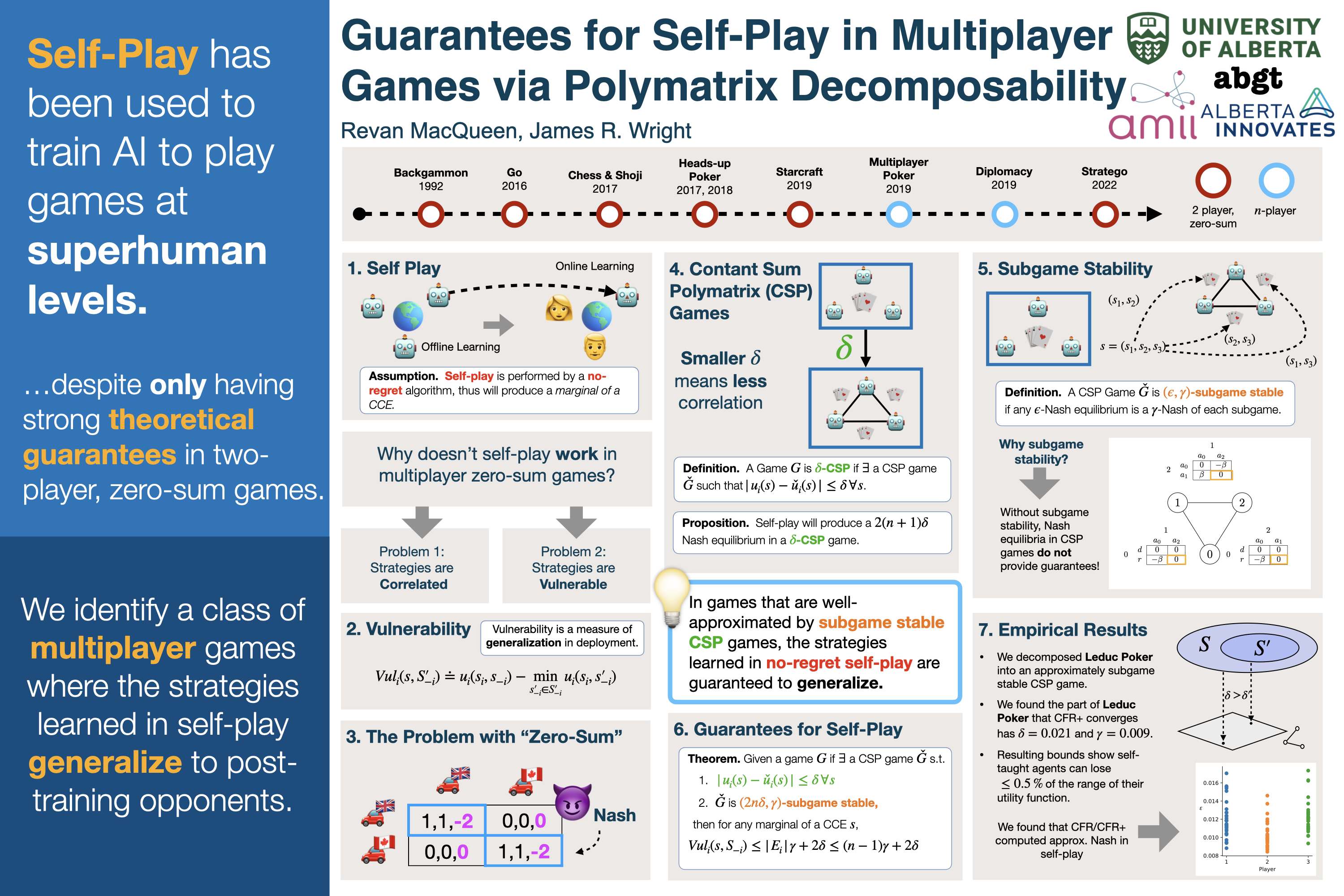
Self-play is a technique for machine learning in multi-agent systems where a learning algorithm learns by interacting with copies of itself. Self-play is useful for generating large quantities of data for learning, but has the drawback that the agents the learner will face post-training may have dramatically different behavior than the learner came to expect by interacting with itself. For the special case of two-player constant-sum games, self-play that reaches Nash equilibrium is guaranteed to produce strategies that perform well against any post-training opponent; however, no such guarantee exists for multiplayer games. We show that in games that approximately decompose into a set of two-player constant-sum games (called constant-sum polymatrix games) where global $\epsilon$-Nash equilibria are boundedly far from Nash equilibria in each subgame (called subgame stability), any no-external-regret algorithm that learns by self-play will produce a strategy with bounded vulnerability. For the first time, our results identify a structural property of multiplayer games that enable performance guarantees for the strategies produced by a broad class of self-play algorithms. We demonstrate our findings through experiments on Leduc poker.
Video
Chat is not available.
Successful Page Load