Sample Complexity of Forecast Aggregation
Tao Lin ⋅ Yiling Chen
2023 Spotlight Poster
{kind=link}
Abstract
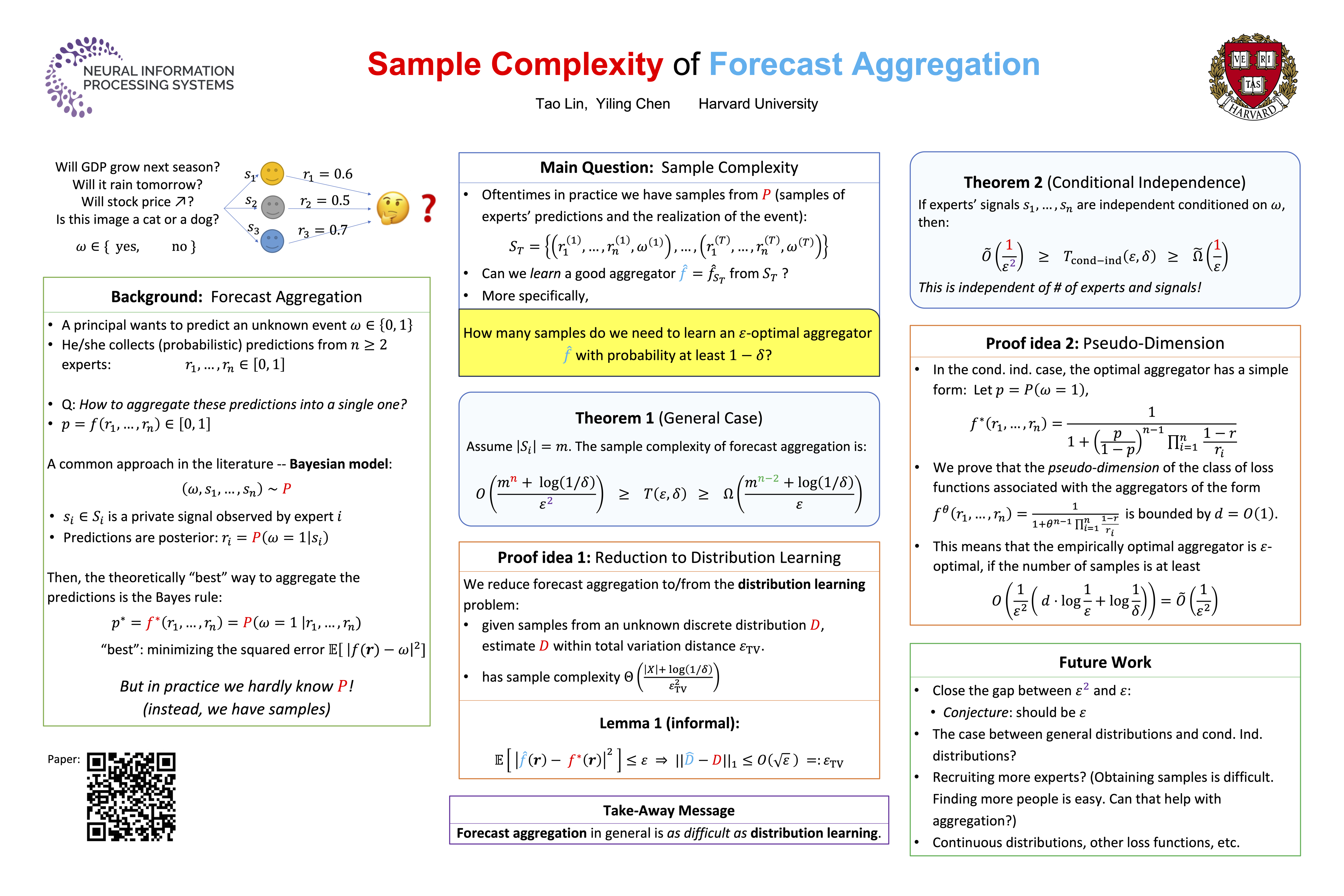
We consider a Bayesian forecast aggregation model where $n$ experts, after observing private signals about an unknown binary event, report their posterior beliefs about the event to a principal, who then aggregates the reports into a single prediction for the event. The signals of the experts and the outcome of the event follow a joint distribution that is unknown to the principal, but the principal has access to i.i.d. "samples" from the distribution, where each sample is a tuple of the experts' reports (not signals) and the realization of the event. Using these samples, the principal aims to find an $\varepsilon$-approximately optimal aggregator, where optimality is measured in terms of the expected squared distance between the aggregated prediction and the realization of the event. We show that the sample complexity of this problem is at least $\tilde \Omega(m^{n-2} / \varepsilon)$ for arbitrary discrete distributions, where $m$ is the size of each expert's signal space. This sample complexity grows exponentially in the number of experts $n$. But, if the experts' signals are independent conditioned on the realization of the event, then the sample complexity is significantly reduced, to $\tilde O(1 / \varepsilon^2)$, which does not depend on $n$. Our results can be generalized to non-binary events. The proof of our results uses a reduction from the distribution learning problem and reveals the fact that forecast aggregation is almost as difficult as distribution learning.
Video
Chat is not available.
Successful Page Load