Revisit Weakly-Supervised Audio-Visual Video Parsing from the Language Perspective
{kind=link}
Abstract
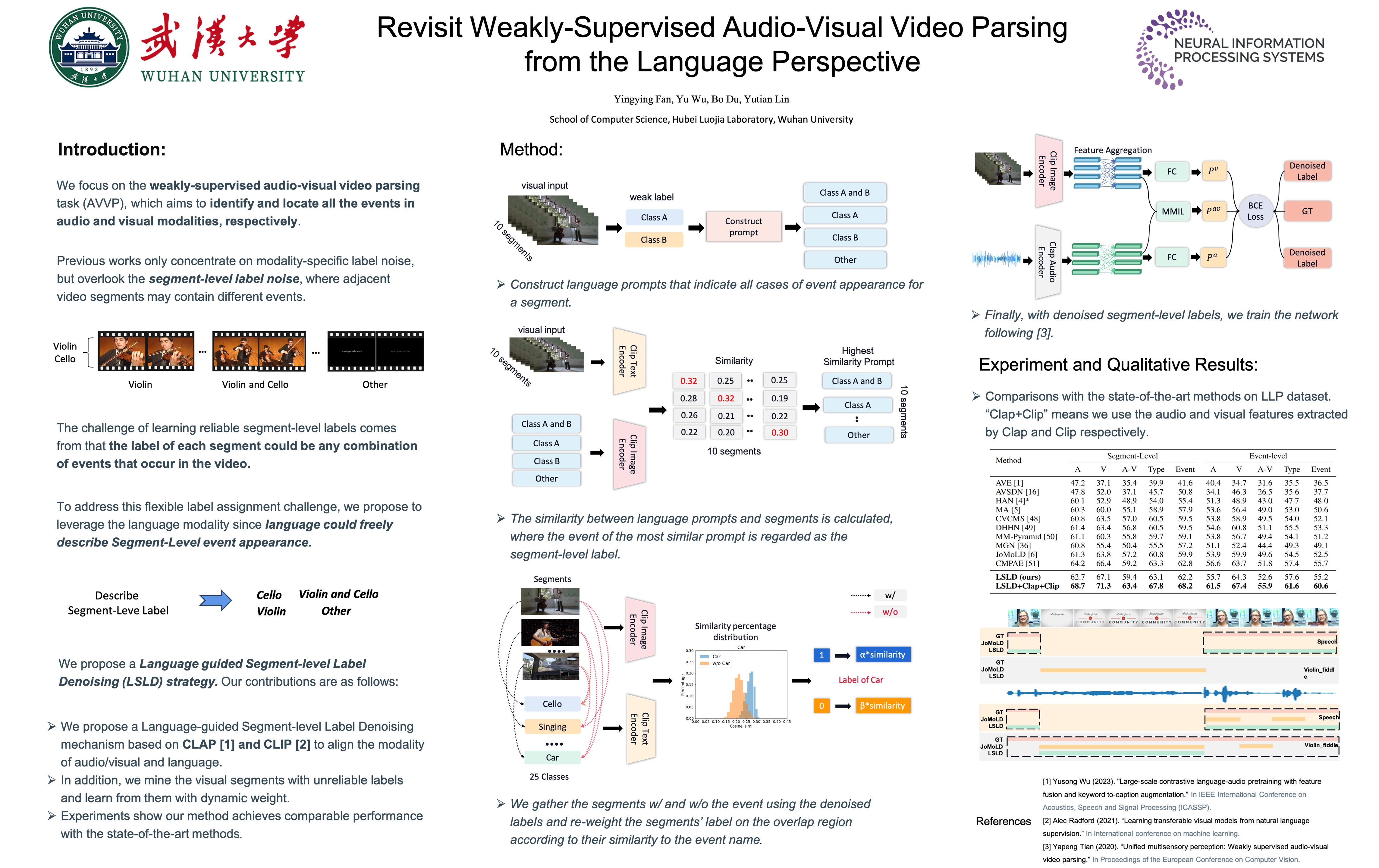
We focus on the weakly-supervised audio-visual video parsing task (AVVP), which aims to identify and locate all the events in audio/visual modalities. Previous works only concentrate on video-level overall label denoising across modalities, but overlook the segment-level label noise, where adjacent video segments (i.e., 1-second video clips) may contain different events. However, recognizing events on the segment is challenging because its label could be any combination of events that occur in the video. To address this issue, we consider tackling AVVP from the language perspective, since language could freely describe how various events appear in each segment beyond fixed labels. Specifically, we design language prompts to describe all cases of event appearance for each video. Then, the similarity between language prompts and segments is calculated, where the event of the most similar prompt is regarded as the segment-level label. In addition, to deal with the mislabeled segments, we propose to perform dynamic re-weighting on the unreliable segments to adjust their labels. Experiments show that our simple yet effective approach outperforms state-of-the-art methods by a large margin.