$SE(3)$ Equivariant Convolution and Transformer in Ray Space
Yinshuang Xu ⋅ Jiahui Lei ⋅ Kostas Daniilidis
2023 Spotlight Poster
{kind=link}
Abstract
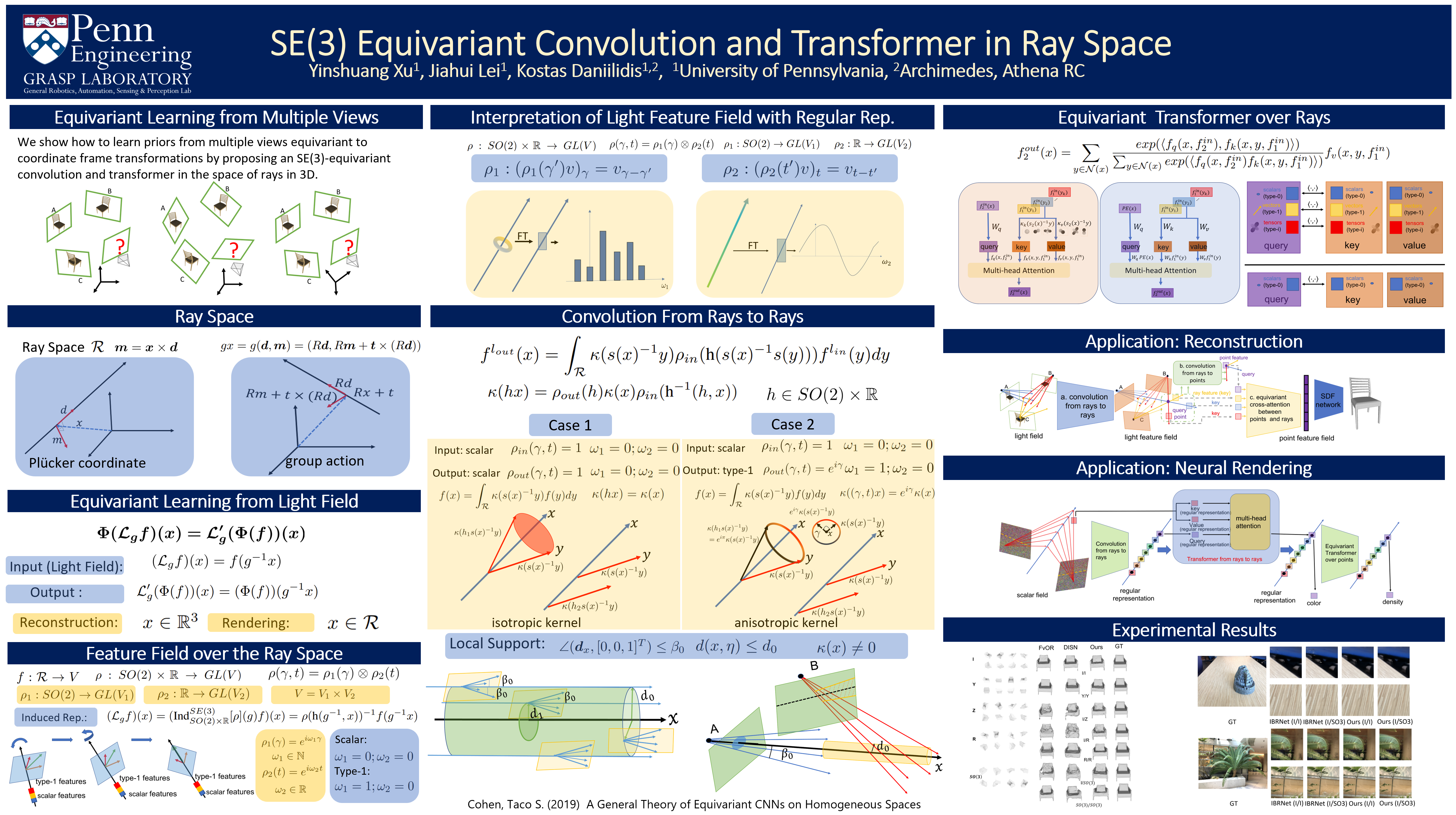
3D reconstruction and novel view rendering can greatly benefit from geometric priors when the input views are not sufficient in terms of coverage and inter-view baselines. Deep learning of geometric priors from 2D images requires each image to be represented in a $2D$ canonical frame and the prior to be learned in a given or learned $3D$ canonical frame. In this paper, given only the relative poses of the cameras, we show how to learn priors from multiple views equivariant to coordinate frame transformations by proposing an $SE(3)$-equivariant convolution and transformer in the space of rays in 3D. We model the ray space as a homogeneous space of $SE(3)$ and introduce the $SE(3)$-equivariant convolution in ray space. Depending on the output domain of the convolution, we present convolution-based $SE(3)$-equivariant maps from ray space to ray space and to $\mathbb{R}^3$. Our mathematical framework allows us to go beyond convolution to $SE(3)$-equivariant attention in the ray space. We showcase how to tailor and adapt the equivariant convolution and transformer in the tasks of equivariant $3D$ reconstruction and equivariant neural rendering from multiple views. We demonstrate $SE(3)$-equivariance by obtaining robust results in roto-translated datasets without performing transformation augmentation.
Video
Chat is not available.
Successful Page Load