Inverse Dynamics Pretraining Learns Good Representations for Multitask Imitation
{kind=link}
Abstract
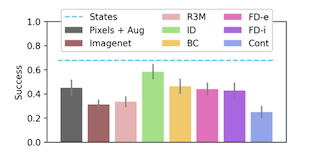
In recent years, domains such as natural language processing and image recognition have popularized the paradigm of using large datasets to pretrain representations that can be effectively transferred to downstream tasks. In this work we evaluate how such a paradigm should be done in imitation learning, where both pretraining and finetuning data are trajectories collected by experts interacting with an unknown environment. Namely, we consider a setting where the pretraining corpus consists of multitask demonstrations and the task for each demonstration is set by an unobserved latent context variable. The goal is to use the pretraining corpus to learn a low dimensional representation of the high dimensional (e.g., visual) observation space which can be transferred to a novel context for finetuning on a limited dataset of demonstrations. Among a variety of possible pretraining objectives, we argue that inverse dynamics modeling -- i.e., predicting an action given the observations appearing before and after it in the demonstration -- is well-suited to this setting. We provide empirical evidence of this claim through evaluations on a variety of simulated visuomotor manipulation problems. While previous work has attempted various theoretical explanations regarding the benefit of inverse dynamics modeling, we find that these arguments are insufficient to explain the empirical advantages often observed in our settings, and so we derive a novel analysis using a simple but general environment model.