Flexible Attention-Based Multi-Policy Fusion for Efficient Deep Reinforcement Learning
{kind=link}
Abstract
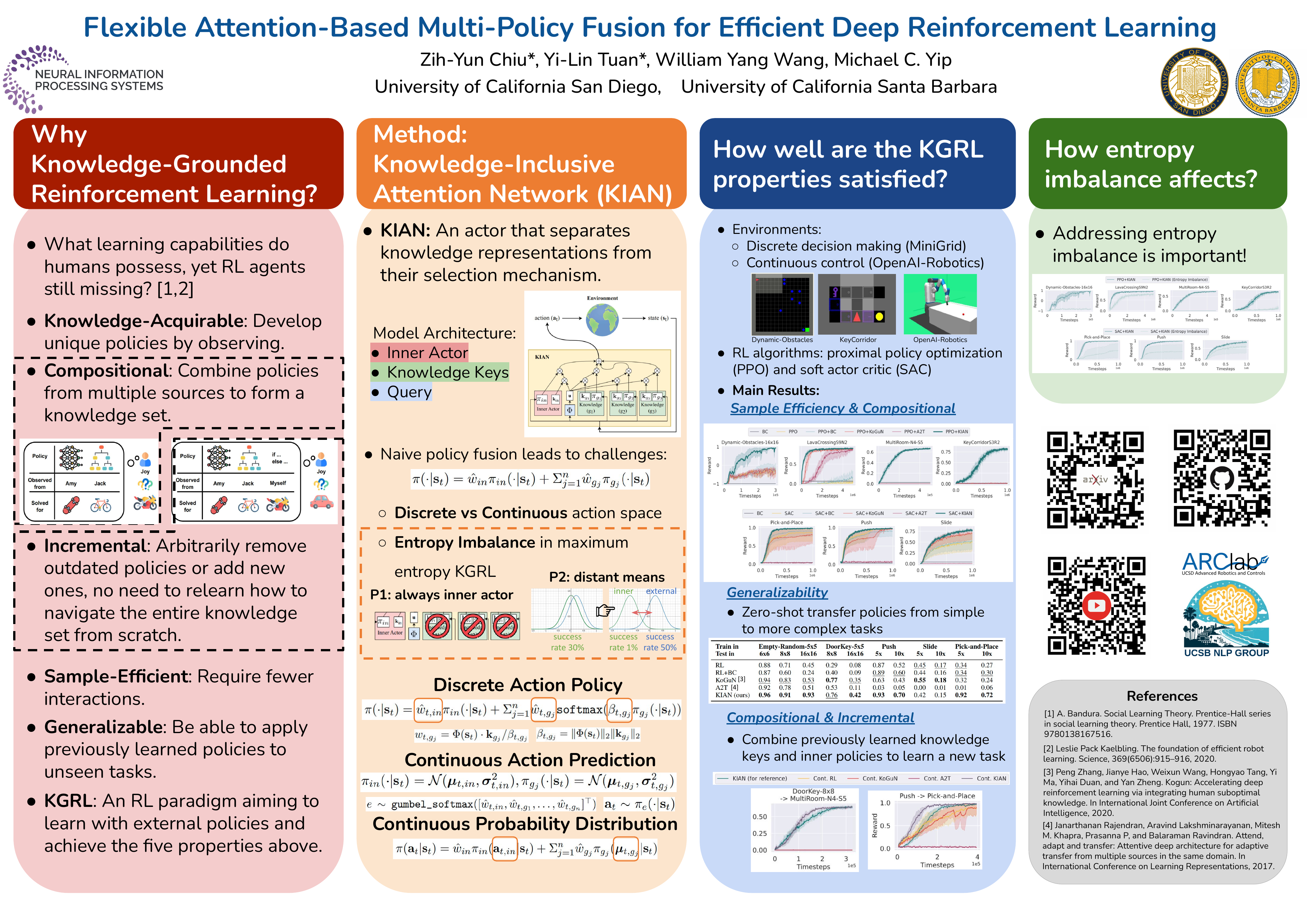
Reinforcement learning (RL) agents have long sought to approach the efficiency of human learning. Humans are great observers who can learn by aggregating external knowledge from various sources, including observations from others' policies of attempting a task. Prior studies in RL have incorporated external knowledge policies to help agents improve sample efficiency. However, it remains non-trivial to perform arbitrary combinations and replacements of those policies, an essential feature for generalization and transferability. In this work, we present Knowledge-Grounded RL (KGRL), an RL paradigm fusing multiple knowledge policies and aiming for human-like efficiency and flexibility. We propose a new actor architecture for KGRL, Knowledge-Inclusive Attention Network (KIAN), which allows free knowledge rearrangement due to embedding-based attentive action prediction. KIAN also addresses entropy imbalance, a problem arising in maximum entropy KGRL that hinders an agent from efficiently exploring the environment, through a new design of policy distributions. The experimental results demonstrate that KIAN outperforms alternative methods incorporating external knowledge policies and achieves efficient and flexible learning. Our implementation is available at https://github.com/Pascalson/KGRL.git .