Softmax Output Approximation for Activation Memory-Efficient Training of Attention-based Networks
{kind=link}
Abstract
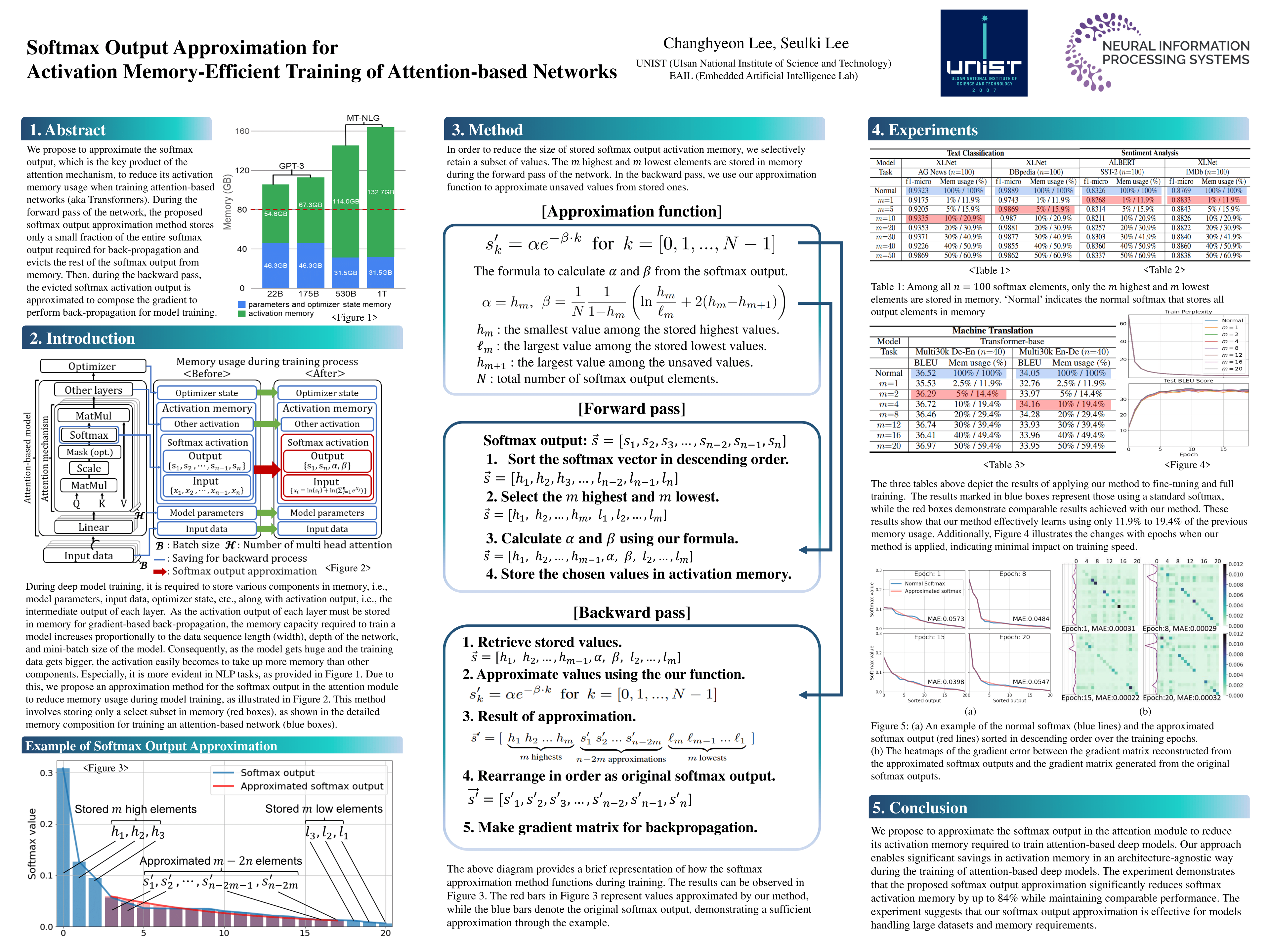
In this paper, we propose to approximate the softmax output, which is the key product of the attention mechanism, to reduce its activation memory usage when training attention-based networks (aka Transformers). During the forward pass of the network, the proposed softmax output approximation method stores only a small fraction of the entire softmax output required for back-propagation and evicts the rest of the softmax output from memory. Then, during the backward pass, the evicted softmax activation output is approximated to compose the gradient to perform back-propagation for model training. Considering most attention-based models heavily rely on the softmax-based attention module that usually takes one of the biggest portions of the network, approximating the softmax activation output can be a simple yet effective way to decrease the training memory requirement of many attention-based networks. The experiment with various attention-based models and relevant tasks, i.e., machine translation, text classification, and sentiment analysis, shows that it curtails the activation memory usage of the softmax-based attention module by up to 84% (6.2× less memory) in model training while achieving comparable or better performance, e.g., up to 5.4% higher classification accuracy.