Rank-1 Matrix Completion with Gradient Descent and Small Random Initialization
{kind=link}
Abstract
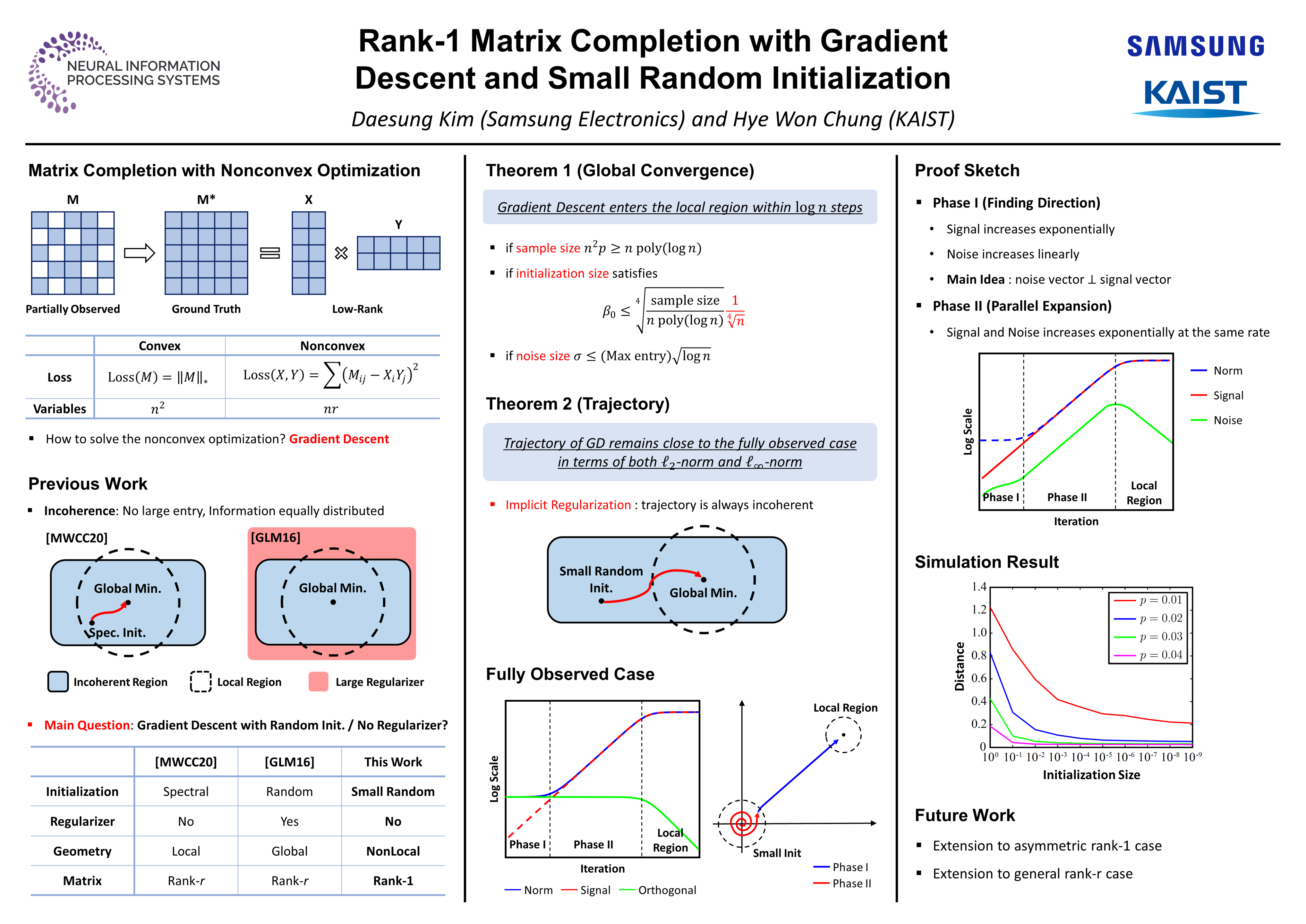
The nonconvex formulation of the matrix completion problem has received significant attention in recent years due to its affordable complexity compared to the convex formulation. Gradient Descent (GD) is a simple yet efficient baseline algorithm for solving nonconvex optimization problems. The success of GD has been witnessed in many different problems in both theory and practice when it is combined with random initialization. However, previous works on matrix completion require either careful initialization or regularizers to prove the convergence of GD. In this paper, we study the rank-1 symmetric matrix completion and prove that GD converges to the ground truth when small random initialization is used. We show that in a logarithmic number of iterations, the trajectory enters the region where local convergence occurs. We provide an upper bound on the initialization size that is sufficient to guarantee the convergence, and show that a larger initialization can be used as more samples are available. We observe that the implicit regularization effect of GD plays a critical role in the analysis, and for the entire trajectory, it prevents each entry from becoming much larger than the others.