FAMO: Fast Adaptive Multitask Optimization
Bo Liu ⋅ Yihao Feng ⋅ Peter Stone ⋅ Qiang Liu
2023 Poster
{kind=link}
Abstract
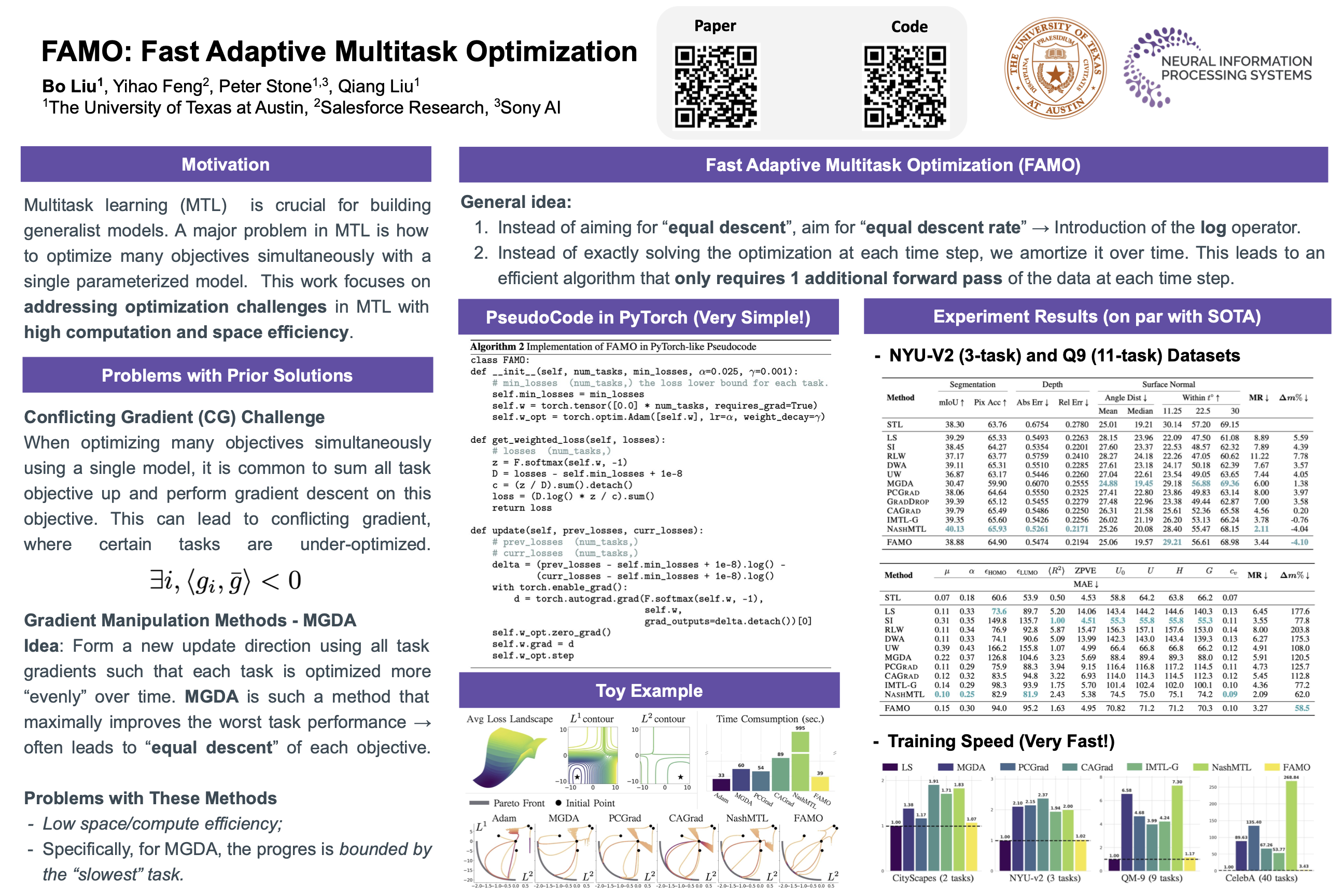
One of the grand enduring goals of AI is to create generalist agents that can learn multiple different tasks from diverse data via multitask learning (MTL). However, in practice, applying gradient descent (GD) on the average loss across all tasks may yield poor multitask performance due to severe under-optimization of certain tasks. Previous approaches that manipulate task gradients for a more balanced loss decrease require storing and computing all task gradients ($\mathcal{O}(k)$ space and time where $k$ is the number of tasks), limiting their use in large-scale scenarios. In this work, we introduce Fast Adaptive Multitask Optimization (FAMO), a dynamic weighting method that decreases task losses in a balanced way using $\mathcal{O}(1)$ space and time. We conduct an extensive set of experiments covering multi-task supervised and reinforcement learning problems. Our results indicate that FAMO achieves comparable or superior performance to state-of-the-art gradient manipulation techniques while offering significant improvements in space and computational efficiency. Code is available at \url{https://github.com/Cranial-XIX/FAMO}.
Video
Chat is not available.
Successful Page Load