Poster
in
Workshop: Deep Reinforcement Learning Workshop
Scaling up and Stabilizing Differentiable Planning with Implicit Differentiation
Linfeng Zhao · Huazhe Xu · Lawson Wong
{kind=link}
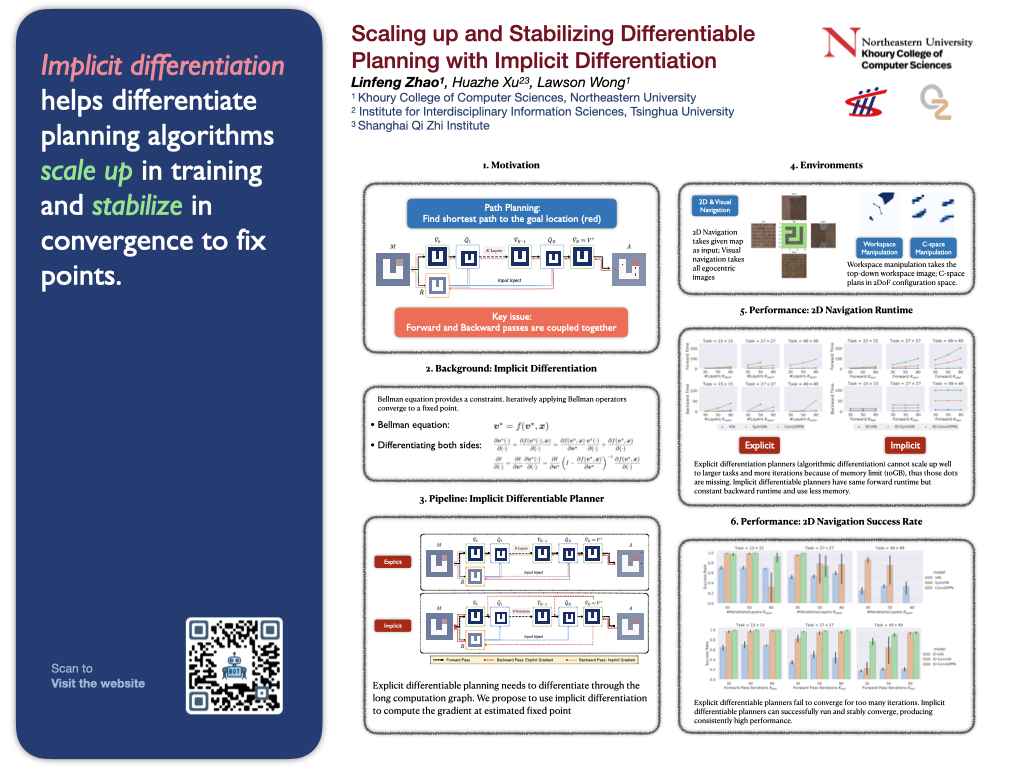
Differentiable planning promises end-to-end differentiability and adaptivity.However, an issue prevents it from scaling up to larger-scale problems: theyneed to differentiate through forward iteration layers to compute gradients, which couples forward computation and backpropagation and needs to balance forward planner performance and computational cost of the backward pass.To alleviate this issue, we propose to differentiate through the Bellman fixed-point equation to decouple forward and backward passes for Value Iteration Network and its variants, which enables constant backward cost (in planning horizon) and flexible forward budget and helps scale up to large tasks.We study the convergence stability, scalability, and efficiency of the proposed implicit version of VIN and its variants and demonstrate their superiorities on a range of planning tasks: 2D navigation, visual navigation, and 2-DOF manipulation in configuration space and workspace.